The choice of how to encode positional information for transformers has been one of the key components of LLM architectures.
An area that has been interesting to us and others in the community recently is whether LLMs can be extended to longer contexts.
We have conducted a range of experiments with different schemes for extending context length capabilities of Llama, which has been pretrained on 2048 context length with the RoPE (Rotary Position Embedding) encoding. Here we share some of the results as well as the training and evaluation scripts in the hope that it will be useful to the community. For our best performing models - linear scaling with IFT at scales 4 and 16 - we are also sharing the weights in case others wish to use them, or to conduct their own tests. We believe the scale 16 model should perform well on real world tasks up to 16k context lengths, and potentially even up to about 20-24k context lengths.
We conducted a wide variety of experiments to try to extend the context length of the models. First, we tried simply using the base Llama model zero-shot. As expected, this performed well up to 2048 context length but deterioriated very rapidly afterwards.
We next investigated fine tuning approaches where we trained the model on the RedPajama dataset at context lengths of 4096. This led to expected improvements in performance up to 4096 context but again, no further.
Another approach to extending context length is to modify in some way the RoPE encoding. Here, we tried many different ideas:
- Linear scaling, as described by kaiokendev.github.io.
- Scaling the Fourier basis of RoPE by a power, such that low frequencies are stretched more than high frequencies.
- Applying truncation to the Fourier basis. Our idea here was that we wanted the model to see only frequencies that were fast enough so that it got at least one full cycle during training; any slower frequencies were set to 0 (equivalent to no rotation at all, i.e. equally important at all context lengths).
- Randomising the position vector.
In particular, we combined fine-tuning on the RedPajama dataset and instruction-fine-tuning with the Vicuna dataset with the above approaches. This is what led to the most fruitful results.
Finally, we implemented and tried the approach described in the xPos paper. This approach adds decaying amplitude penalty terms that cause fast frequencies to have less impact at long distances than slow frequencies in the Fourier basis (see our blog post for similarity heatmaps that show this).
Perhaps the most pointed observation we made is that different evaluation methodologies/tasks lead to different rankings of the approaches detailed above. This will be described in further detail below.
That said, we made the following general observations:
- Linear interpolation/scaling seems to be the most robust approach for increasing model context length.
- Using a linear scale of N does not necessarily lead to a model context length increase by a factor of N. For example, our scale 16 experiments generally stopped performing well after a context length of 16000, not 32000 (~2048 * 16). We have ideas for how to ameliorate this effect planned for future work.
- Truncation and randomisation both seem to have great perplexity scores but perform less well on the retrieval task.
- Instruction fine tuning with the Vicuna dataset improves accuracy in the retrieval context significantly at lengths which the base model is capable of handling, but cannot 'fix' the base model at lengths where it fails.
For evaluation we used two different datasets:
- LMSys datasets (the 'lines' task) for locating a substring in the context
- Our own open book question answering dataset, WikiQA, which is based off of other open source base QA datasets
In addition, we looked at the log loss of the train and eval sets during
For the LMSys task, we generated new and longer testcases, up to a context length of about 25000, beyond the 16000 context testcases in the original dataset.
The WikiQA task is the task of answering a question based on the information given in a Wikipedia document. We have built upon the short answer format data in Google Natural Questions to construct our QA task. It is formatted as a document and a question. We ensure the answer to the question is a short answer which is either a single word or a small sentence directly cut pasted from the document. Having the task structured as such, we can pinpoint exactly where the LLM was supposed to "look" for the answer in the context, and thus effectively evaluate every part of the expanded context length by carefully placing the answer in different locations.
We have selected large Wikipedia documents and have truncated them to get multiple versions of the same document with sizes varying between 2000 to 16000 tokens. For each size of the document, we also have multiple versions which place the question and the answer text at different locations i.e whether it occurs in the first 10%, the bulk or last 10% of the document. Having multiple version of the same document allows us to get a exhaustive and fair evaluation across model sizes, and within one model's context positions since we intrinsically are asking for the same information.
A potential issue in a Wikipedia based dataset is that the model could perhaps correctly answer from its pretrained corpus and not from context. To resolve this, we have created another “altered” dataset. This data only consists of questions which have numerical answers. Here, we change the answer and every occurrence of the answer in the document to a different number. Essentially making sure that if the LLM recollects from its pretrained corpus, it gives a wrong answer. The modification is made as follows:
- If the answer is a year, which is quite frequent, (i.e. is between 1000-2100), we change it to a different random value within +/- 10 of the original value. We treat years as a special case so as to not make the interpretation of the document absurd by messing up choronological information
- If the answer is any other number, we change it to a different random number which has the same number of digits
We call our original QA task Free Form QA (FFQA) and the altered task Altered Numeric QA (AltQA).
We evaluate success on every example in both versions of our QA task by measuring "Presence Accuracy" i.e, whether or not the answer is present as a subtring in the model's generated answer. To run inference for our models on WikiQA and compute metrics refer to run_inference_WikiQA.py and compute_metrics_WikiQA.ipynb here
We are releasing these datasets on HuggingFace so others can use it to run their own long context experiments.
As a general point regarding the results below, the authors believe that small differences in accuracy on this task are not particularly indicative of model ranking quality. We would generally look at the broadest trends here in interpreting the results.
Also, as a baseline, standard Llama-13b only has non-zero accuracy up to 2048 context length (as does the Vicuna-instruction- fine-tuned version of it).
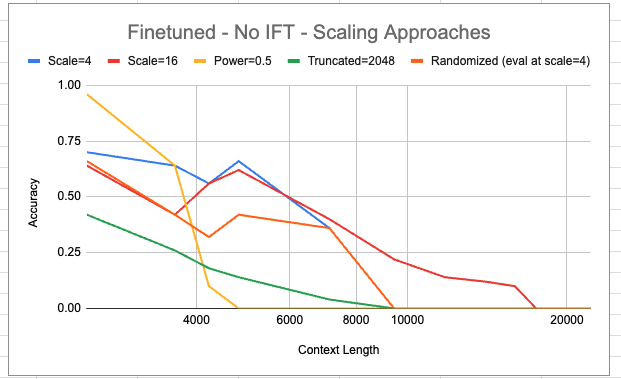
In the above we compare the different scaling approaches. 'Scale' refers to linear interpolation with the designated scaling value. We see that linear interpolation with a scale of 16 is the only one to achieve a non-zero accuracy at context lengths greater than 9000. However, this seems to come with a sacrifice of some accuracy on shorter contexts.
The power = 0.5 basis seems to work particularly well for this task at shorter contexts but has the sharpest drop off in accuracy as context length increases.
It's interesting to note that scale=16 doesn't generalise quite as far as one would hope. Naively, one expects that following the trend of scale=4 - which is non-zero up to 8192 (and this is reasonable as the original context length is 2048, and 8192 = 2048 * 4; beyond this, the model is seeing relative distances between keys and queries it has never encountered before), scale=16 should be non-zero all the way up to 2048 * 16 = 32768.

In the above we display the impact of IFT via training with the Vicuna instruction set using LoRA. We see that IFT does improve accuracy by a small but non-negligible margin. However, it is not sufficient to change the overall shape of the accuracy curve - and it does not confer any extension to the range of context lengths the model can achieve non-zero accuracy on this task at.

In the above, we display various experiments with trying different scale values (for linear interpolation) at evaluation time than the model was trained on. The green curve is indicative of taking a base model (trained on 2048 context) and applying a scale value to it. It does extend the non-zero range from 2048 to 4096, but with low accuracy throughout. In general, however, once a model has been trained with a scale > 0, it seems that the model can then zero-shot to a larger scale at evaluation time quite well - very greatly increasing the range of coherent context lengths (e.g. compare Train=4, Eval=8 being non-zero here at 16k context length vs being 0 for anything above 8k two graphs above). However this does come at the cost of accuracy dropoff, particularly for Train=16, Eval=32.
The Train=16, Eval=12 run has the longest non-zero accuracy context length we have seen. It achieves a non-zero score at a context length of around 20000.
In the below tables, both models are evaluated with scale=4. However, the 'no scaling' model was no finetuned (i.e. experienced no training) at a scale > 1. The Scale=4 model did receive finetuning at that expanded scale.
Presence Accuracy:
| Context Length | IFT with Scale=4 on FFQA | IFT No scaling on FFQA | IFT with Scale=4 on AltQA | IFT No scaling on AltQA |
|---|---|---|---|---|
| 2048 | 0.3233 | 0.2217 | 0.7281 | 0.2982 |
| 4096 | 0.3783 | 0.2467 | 0.7018 | 0.2829 |
| 8192 | 0.4434 | 0.2406 | 0.6582 | 0.2401 |
| 16384 | 0.3933 | 0.0 | 0.5363 | 0.0 |
Note: For 16k context length, we use a scale factor of 8 during inference. This enables expanding the original 2k context to 2*8=16k. It is interesting to point out that even though the scaled model was trained with a scale factor of 4, it can zero-shot interpolate to 16k (a scale of 8) during inference without losing too much performance. This however does not hold in the non-scaled models as is evident from the drop in accracy to 0 on the 16k datapoints. Indicating that our scaling and context length interpolation does work.
As mentioned previously, we truncate and modify the documents to have different version of the WikiQA data. Each version is meant to extensively test the model's performance upto and at a certain context length as indicated by the version name
| Mean Context Length | Max Context Length | |
|---|---|---|
| ffqa_2k.json | 1936.71 | 3228 |
| ffqa_4k.json | 3805.06 | 5793 |
| ffqa_8k.json | 7598.98 | 9963 |
| ffqa_16k.json | 15000.54 | 16178 |
| Mean Context Length | Max Context Length | |
|---|---|---|
| altqa_2k.json | 1953.73 | 2698 |
| altqa_4k.json | 3737.39 | 5172 |
| altqa_8k.json | 7481.37 | 9619 |
| altqa_16k.json | 15013.44 | 16173 |
As is seen above, our technique of finetuning interpolated embeddings seems to give good models robust to increasing context length of inputs on the WikiQA task. We demonstrate this on both versions of the task. Since we finetune with a scale context of 4, we expect the accuracy to not drop until 4*2048=8192 sized input. Even beyond this limit, we do see some reasonable performance. This seems to be a consequence of the periodicity of RoPE embeddings, which leads to some characteristics being extrapolatable to positions beyond the limit set by the scale context
We contrast models instruct finetuned with and without scale context to show that IFT with scaled context leads to a significant jump in performance. Note that for both models, we still use a scaled context (=4) during evaluation. Interestingly, even zero shot performance of the scaled RoPE embedding gives non-trivial accuracy. However, having the embeddings explictly finetuned does have considerable gains. We see almost a 2x improvement on FFQA and a 2.5x improvement on AltQA at all positions interpolated by the scale context factor
We trained models across all the experiment described in the overview. Not all of them seem promising for a full evaluation. Some of the experiments were abandoned because the loss curves did not seem promising. In some cases we did find that the results did not alway align with the losses we were observing during training.
The images below show curves from a subset of the experiments we ran:

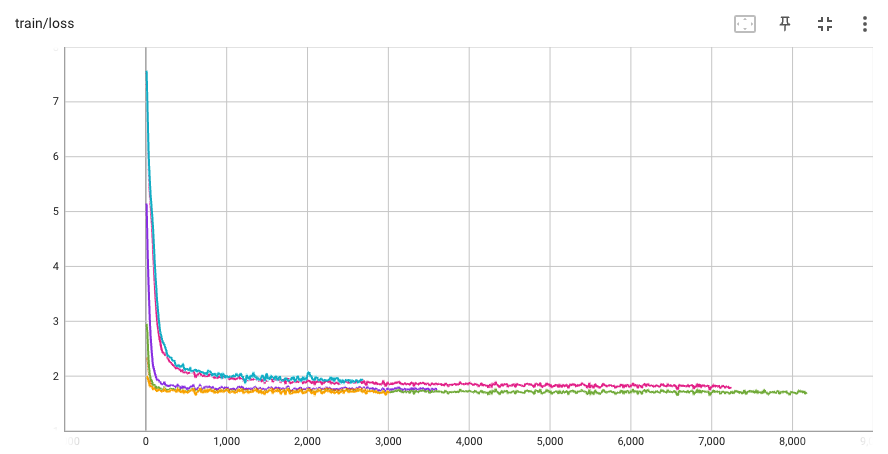

For example the XPOS loss never converged towards the losses seen in the other runs. Initially we suspected that fp16 lacked sufficient precision to handle the XPOS coefficients. We adjusted the implementation to use fp32 for the core attention dot product. This did improve the convergence but not sufficiently to have the losses match the other models. Our hypothesis is that XPOS is too different from the base positional embeddings to finetune into the embedding. This is a bit surprising since XPOS can is just RoPE with a scaling factor that is a function of relative difference. One experiment we started but have not completed is to start with a factor of 1.0 and slowly shift to the XPOS function over iterations.