注:当前项目为 Serverless Devs 应用,由于应用中会存在需要初始化才可运行的变量(例如应用部署地区、函数名等等),所以不推荐直接 Clone 本仓库到本地进行部署或直接复制 s.yaml 使用,强烈推荐通过
s init ${模版名称}的方法或应用中心进行初始化,详情可参考部署 & 体验 。
基于流程构建 RAG 应用
使用该项目,您需要有开通以下服务并拥有对应权限:
| 服务/业务 | 权限 | 相关文档 |
|---|---|---|
| 函数计算 | AliyunFCFullAccess | 帮助文档 计费文档 |
| 云工作流 | AliyunFnFFullAccess | 帮助文档 计费文档 |
| 云数据库RDS | AliyunRDSFullAccess | 帮助文档 计费文档 |
| 对象存储 | AliyunFCServerlessDevsRolePolicy | 帮助文档 计费文档 |
| 日志服务 | AliyunFCServerlessDevsRolePolicy | 帮助文档 计费文档 |
| 专有网络 | AliyunFCServerlessDevsRolePolicy | 帮助文档 计费文档 |
🔥 通过 Dipper 应用中心 ,

-
离线知识库向量化:配置 OSS 触发器,当 OSS bucket 中有文件上传时,自动触发离线知识库处理流程。
- GatewayOSSTriggerStream: 接收 OSS 事件触发请求的网关。当 OSS Bucket 中有 object 上传时,自动触发离线知识库 embedding 流程。
- OfflineFlow: 基于 CloudFlow 的离线数据处理流程。流程负责拉取上传至 OSS 的知识库信息,对文档进行切分,通过 Map-Reduce 将切分后的文本进行向量化处理,并将向量化结果存入向量数据库。
- TextSpliter:拉取 OSS 中的知识库文档,对文档进行切分。
- Embedding: 文本向量化模型。对切分后的文档进行向量化处理。
- PGVectorHelper: 封装了向 PGVector 插入、查找操作的帮助程序。将 Embedding 后的结果存储到向量数据库。
- VectorDB:安装了 Vector 插件的 PostgreSQL RDS 实例。
-
在线问答:聊天页面
- WebUI: 托管的开源 UI 项目 ChatGPT-Next-Web,用于聊天的页面展示。
- OnlineFlow: 基于 CloudFlow 的在线数据处理流程。流程将聊天内容 Embedding,根据余弦相似度查找与用户查询语句相关的上下文,根据上下文构造 Prompt ,传入大语言模型进行推理和生成。
- Embedding: 文本向量化模型。对用户问题进行向量化处理。
- PGVectorHelper: 封装了向 PGVector 插入、查找操作的帮助程序。根据余弦相似度查找与用户查询语句相关的文本。
- PromptBuilder: 提示词生成器,将检索出的知识库内容与 Prompt 模板结合,构造 Prompt 语句。
- LLM: 大语言模型,根据提示词进行推理和生成。
项目部署成功后,您需要先去 OSS 上传知识库,然后通过聊天页面就可以进行问答了
在线问答访问入口:${resources.WebUI.output.customDomain.domainName}
离线 OSS 上传知识库入口:
- 进入 OSS 控制台,找到您配置的 OSS bucket,进入您配置文件前缀对应的目录下上传知识库文档即可。
然后,聊天页面可以根据您的知识库进行在线作答
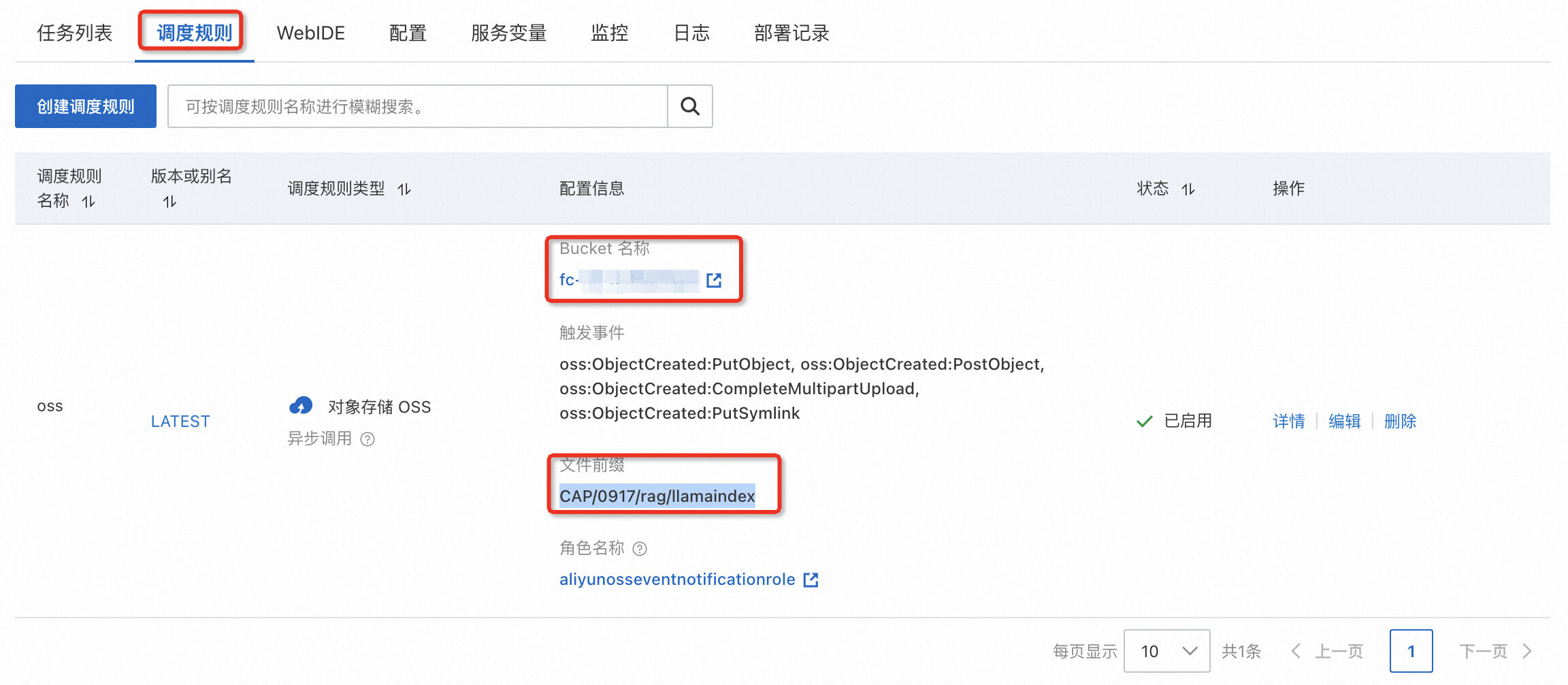
如何在控制台上找到上传知识库的 OSS 地址?
进入名为 GatewayOSSTriggerStream 的服务,进入调度规则,即可以看到对应的 bucket 和文件前缀,您需要进入前缀对应的目录上传知识库文件。
例如:bucket 为 cap-hz,前缀为 test/rag/flow,则进入 cap-hz bucket 中的 test/rag/flow 目录中上传文件即可。
如果 Bucket 下原本没有目录,需要手动创建目录
如何找到聊天页面地址? 找到 WebUI 服务,找到访问入口,在浏览器中打开即可。
RAG(Retrieval-Augmented Generation)应用是一种结合了信息检索(Retrieval)和文本生成(Generation)的人工智能技术。使其能够在生成响应之前引用训练数据来源之外的权威知识库。大型语言模型(LLM)用海量数据进行训练,使用数十亿个参数为回答问题、翻译语言和完成句子等任务生成原始输出。在 LLM 本就强大的功能基础上,RAG 将其扩展为能访问特定领域或组织的内部知识库,所有这些都无需重新训练模型。这是一种经济高效地改进 LLM 输出的方法,让它在各种情境下都能保持相关性、准确性和实用性。
本案例基于阿里云云产品一键拉起 RAG 应用,达到的效果是:您通过上传文本文件(.txt/.pdf 格式)到阿里云 OSS,自动触发函数计算对文件进行切分,存储到向量数据库中。当与机器人进行对话时,会自动从知识库中检索相关的信息,机器人根据上下文并在回答中引用这些信息。
步骤一:上传知识库到 OSS 您可以下载 CAP 简介的知识库文档,上传到您的 OSS Bucket 的指定目录下
步骤二:打开在线聊天入口,与机器人进行对话问答
步骤三:您可以持续上传您的知识库文档进行测试,如果当前模板不满足您的业务需求,您可以对模板进行二次开发。
您如果有关于错误的反馈或者未来的期待,您可以在 Serverless Devs repo Issues 中进行反馈和交流。如果您想要加入我们的讨论组或者了解 FC 组件的最新动态,您可以通过以下渠道进行:
 |
 |
 |
|---|---|---|
微信公众号:serverless |
微信小助手:xiaojiangwh |
钉钉交流群:33947367 |