Knowledge Distillation Meets Self-Supervision & Prime-Aware Adaptive Distillation #75
Comments
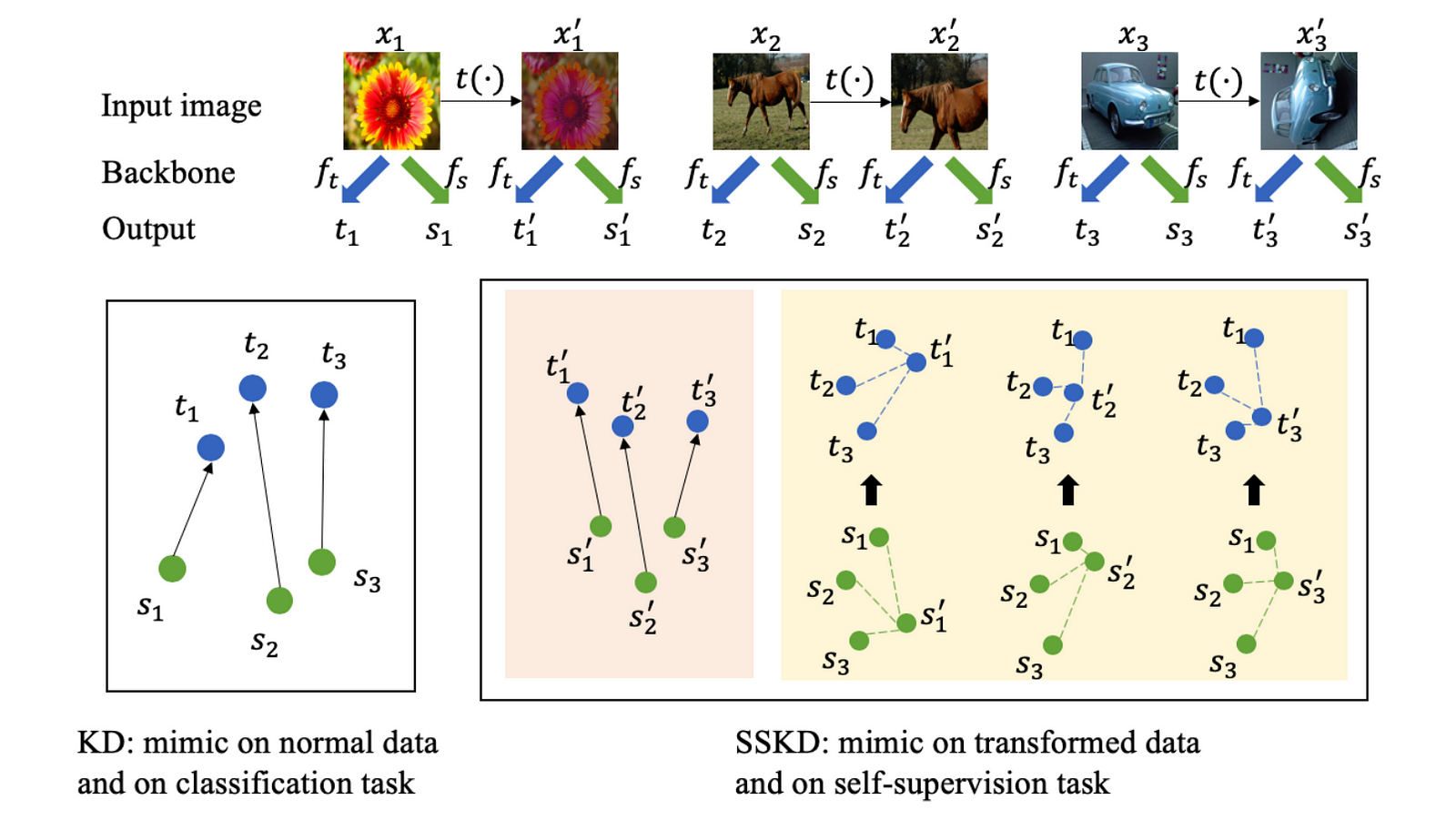
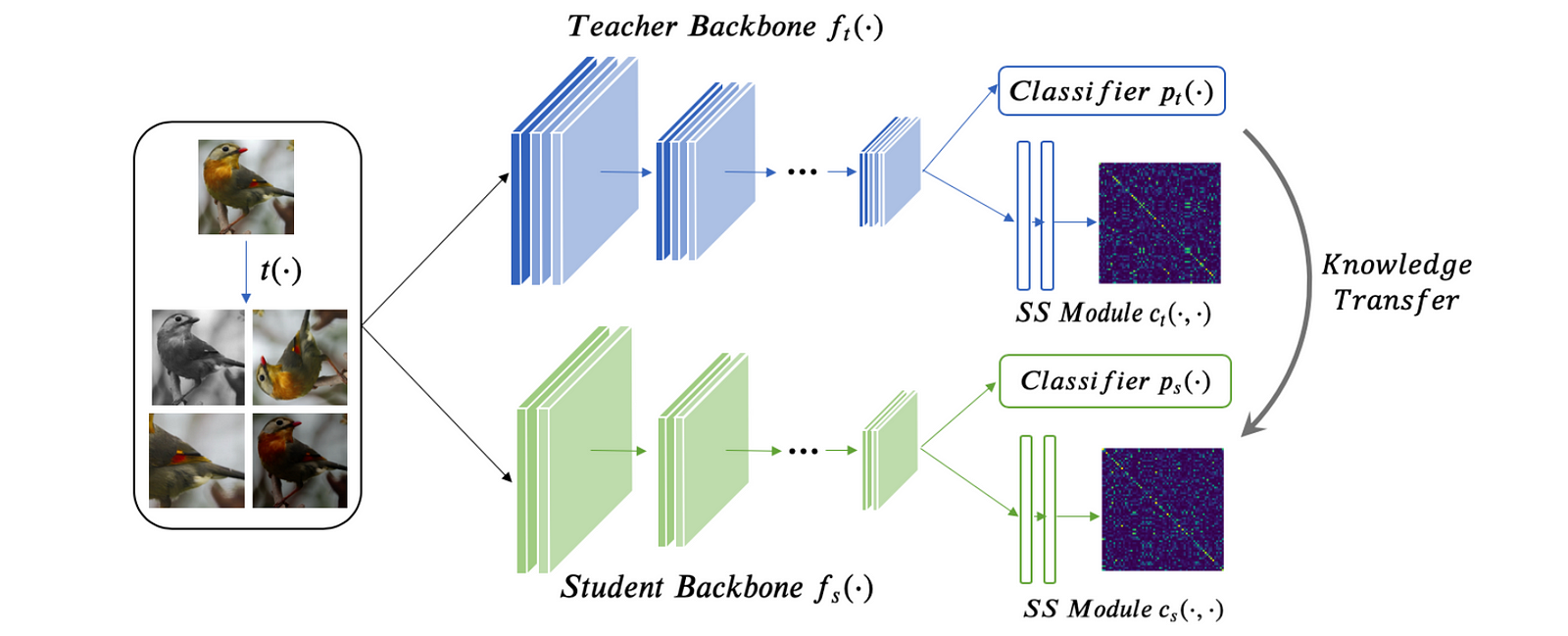
Prior Approaches on Knowledge DistillationBasically, knowledge distillation aims to obtain a smaller student model from typically larger teacher model by matching their information hidden in the model. The information could be: final soft predictions, intermediate features, attentions, relations between samples. See this complete review. Highlights
Methods
|
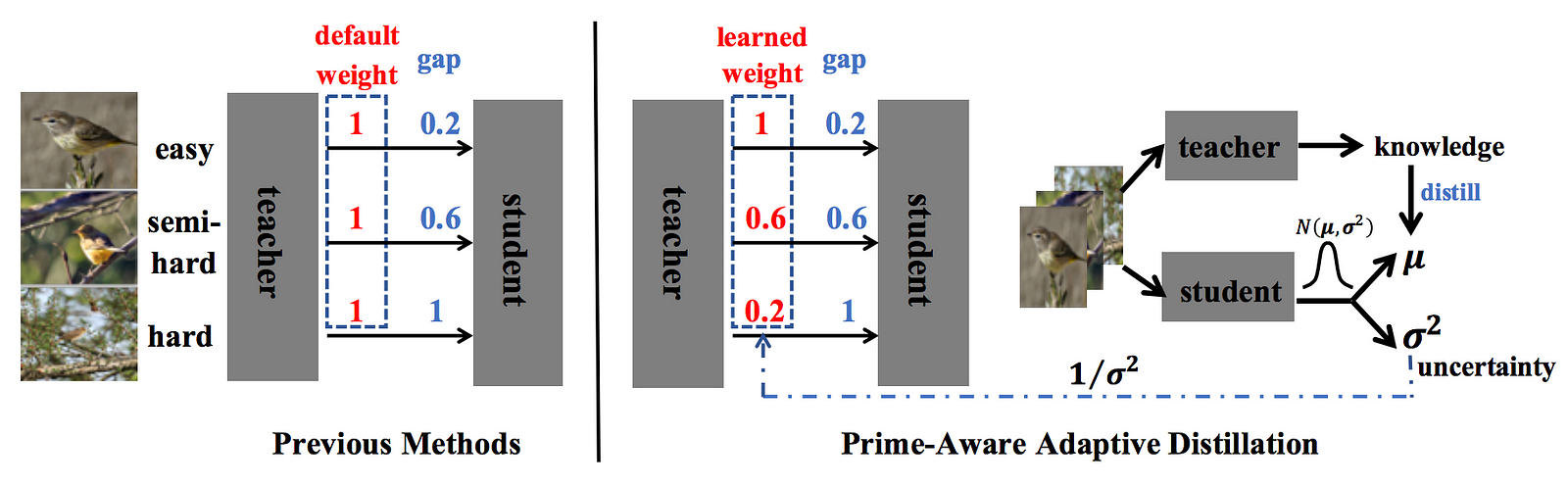
Metadata: Prime-Aware Adaptive Distillation
|
Highlights
Methods
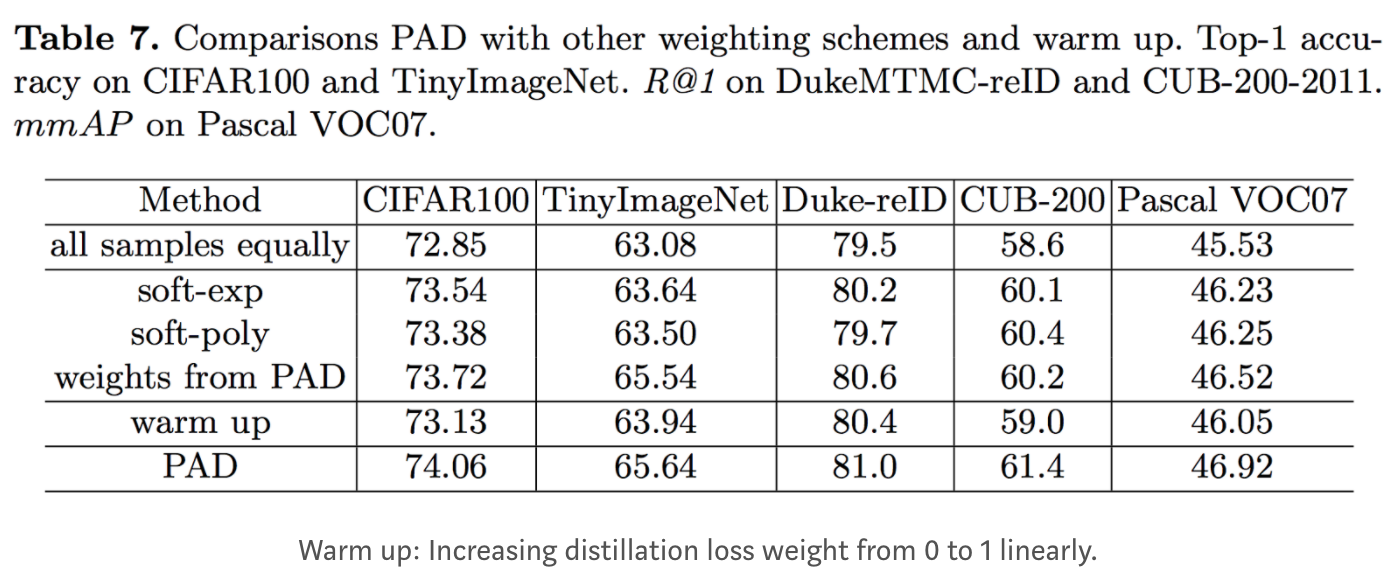
FindingsWhen learning uncertainty var, they found that the var becomes small at the beginning and then stable during PAD training. Therefore they added an additional "warm-up" experiment in the above table and found that it performs slightly better than baselines but worse than the learned weights from PAD. Finally, combining PAD with warm-up training scheduling can achieve better results. |


Further Readings
|
Metadata: Knowledge Distillation Meets Self-Supervision
The text was updated successfully, but these errors were encountered: