Chinese characters #19
Comments
|
Do you mean this tokenizer: https://platform.openai.com/tokenizer ? The above linked tokenizer uses r50k_base as encoding, while gpt-3.5-turbo uses cl100k_base as encoding. Try this one, mentioned in this tiktoken FAQ, for your comparison: https://tiktokenizer.vercel.app/ (make sure to use the textbox input and not the message input if comparing the encoding of a raw string like in your screen) |
|
Solved ! |
Closed
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Hello, it seems that there is a slight difference in the calculation of Chinese characters between this project and the Tokenizer on the official website.
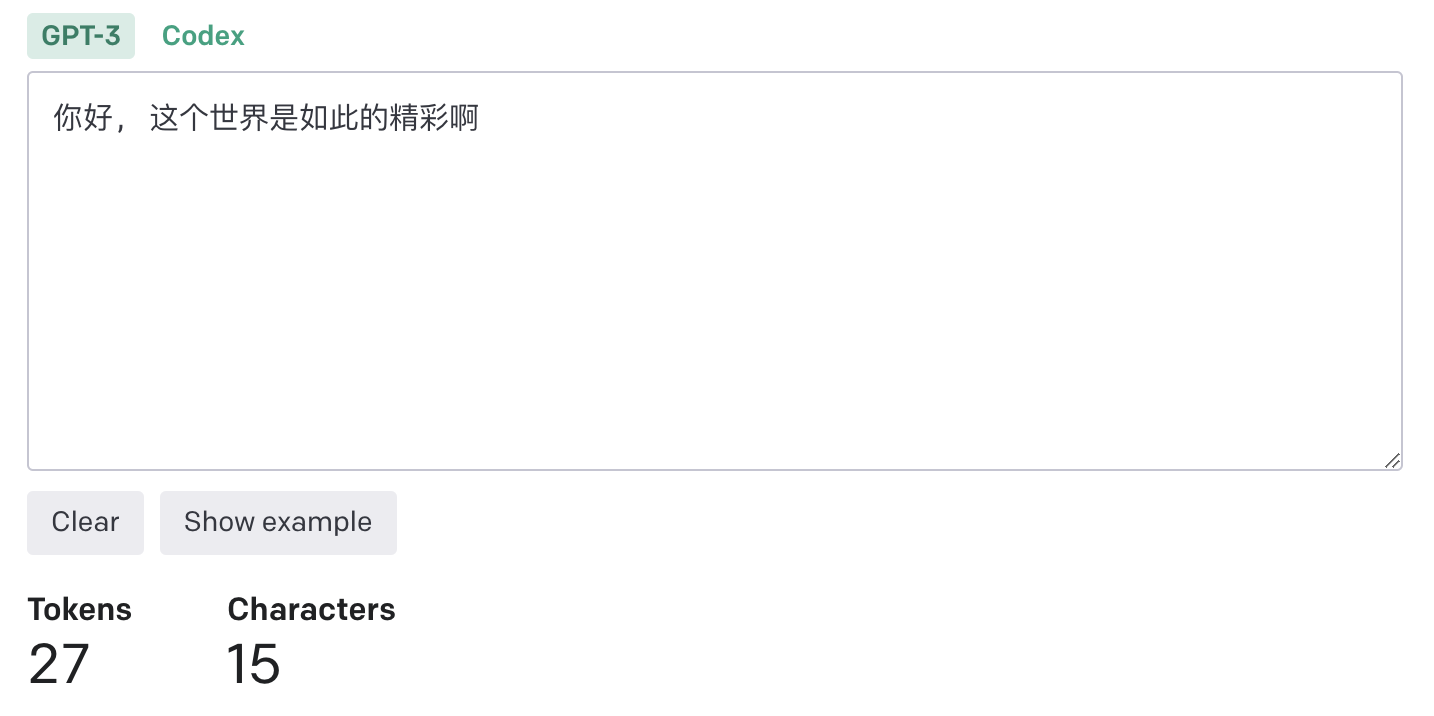

The model I use is
gpt-3.5-turbo, and the following are two comparison pictures:The text was updated successfully, but these errors were encountered: