This is a fork of PhotonVision. It uses the NPU on the RK3588 processor to run object detection models. The expected performance is 60 FPS with a 640x640 model.
- Download the latest image from the releases page.
- Flash the image to an SD card using Balena Etcher.
- Insert the SD card into the board, and turn it on. The default username and password for that image is ubuntu:ubuntu.
- That's it! PhotonVision with the RKNN pipeline should be installed and running on the board.
- Install Ubuntu 22.04 on the board. I recommend this unofficial project. The default username and password for that image is ubuntu:ubuntu. Make sure to use an Ubuntu 22.04 (Jammy) server image.
- Install PhotonVision using the official instructions. This requires you to ssh into the board, which requires you to have the board's IP address. You can do this by connecting the board to a monitor and keyboard and run the
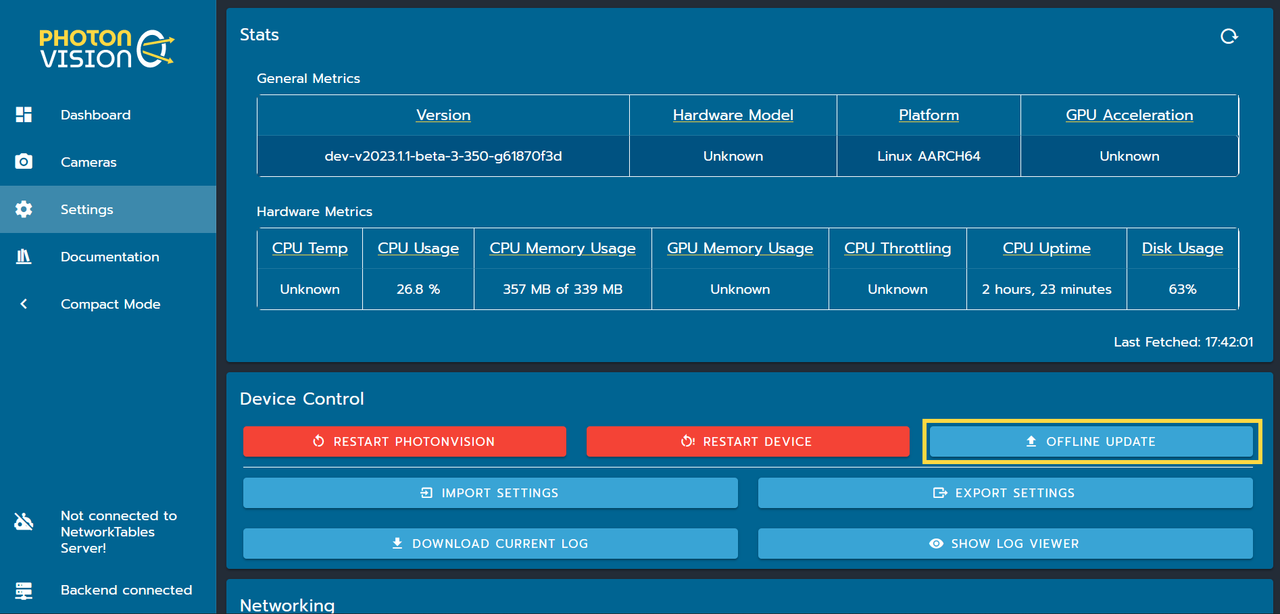
ifconfigcommand, or by using a tool like Angry IP Scanner and be connected to the same network as the board, such as the robot's network. - This gets you to a "stock" PhotonVision installation. In order to get the object detection working, download the latest linuxarm64 jar from the releases page and upload it using the "offline update" button in the setings page:
- That's it! after uploading the jar, PhotonVision will restart automatically, and the RKNN pipeline should be available.
- Go to the "Vision" tab, and click "Add Pipeline". Select "RKNN" as the pipeline type. Alternatively, you can edit an existing pipeline and change the type to "RKNN".
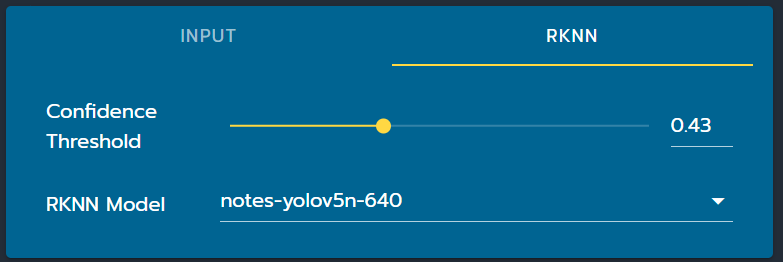
- The default model is YOLOv5n, at 640x640 resolution, detecting notes. You can change the model by going to the RKNN Tab and choosing another model from the dropdown. There, you can also change the confidence threshold.
- To upload a model of your own, head to the settings page, click the "Import Settings" button, and choose "RKNN Model". Choose a model from your computer, and it should upload and restart PhotonVision automatically, and the model should be available in the RKNN tab.
- To use the detection in the robot code, you can use the regular methods to retrieve the target. The get the class and confidence, use the
fiducialIdandposeAmbiguityfields respectively.
- Make sure to use a low enough exposure so that 1000/exposure > the camera fps. For example, if the camera is running at 60 FPS, the exposure should be 16.6ms or lower. If the exposure is too high, the camera will output frames slower than the chosen FPS, and the latency will be higher.
- When the "Processed" tab is hidden, the code doesn't draw the boxes on the image, which saves up to 1ms of latency, thus recommended when used in a competition.
- When the selected stream resolution is not the resolution of the camera input, the code will resize the image, which adds latency. If the camera is used as a driver camera, it is recommended to change it to a lower resolution so the stream would run smoother, but if not, it's best to keep the stream resolution the same as the camera resolution, so the code doesn't resize the image, and save latency.
If you want to use your own YOLOv5/8 model, you can train one and export it to the RKNN format using these Kaggle notebooks. Kaggle is a free service that allows you to train models on the cloud, and it's very easy to use. You can also use your own computer to train the model, but it's recommended to use a GPU, and it's much easier to use Kaggle. Kaggle gives you 30 hours of free GPU time per week, which is more than enough to train a model. You can also use Google Colab, but it's a bit more complicated to use, and offers slower hardware.
- YOLOv5
- YOLOv8
