Bu sefer önceki bölümlerden biraz daha farklı birşey yapacağız.
Şuana kadar yaptığımız tüm pratiklerde, stack üzerinde ortaya çıkan bellek sorunlarını kullandık. Fakat bildiğiniz üzere, stack bir programın kullanabileceği tek bellek alanı değil. O halde başka bir bellek alanından bahsetme zamanı.
Bu seviyenin dizininde (0x6 dizininde) bir pratik söz konusu değil, heap'i anlamak için kullanacağımız bazı
örnekler söz konusu, bunları az sonra inceleyeceğiz.
Çoğunuzun bildiği UNIX-gibi işletim sistemlerinde, heap stackden adres bakımından daha önce gelen, ve stack'in aksine yukarı doğru genişleyen bir veri alanı.
Bunu kernel'in programlara verdiği bellek yapısına bakarak da görebiliriz:
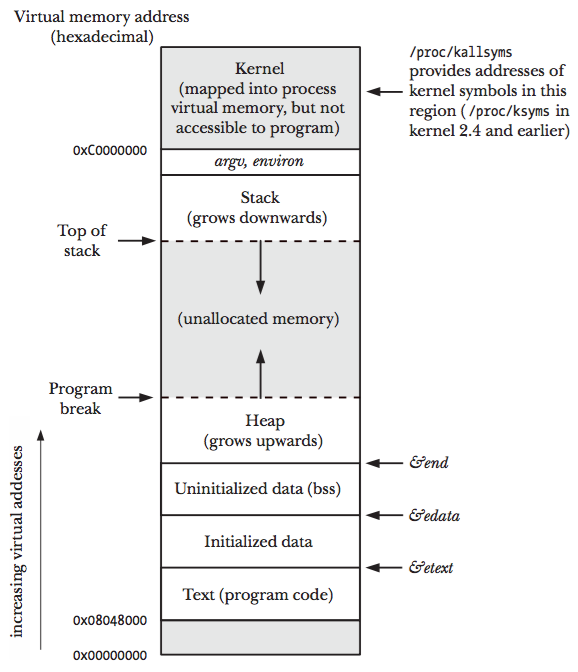
Stack doğrudan stack pointer register'ı aracılığı ile erişilebilir. Ancak heap için bu kadar kolay bir
erişim söz konusu değil. Heap'e erişebilmek için klasik UNIX sistemlerinden kalma "break" sistem çağrsını
kullanıyoruz. Modern UNIX-gibi işletim sistemlerinde bu çağrı sbrk() (set program break) olarak biliniyor.
sbrk() normalde tek bir argüman kabül eden bir sistem çağrısı. Bu argüman basitçe heap'in kaç byte genişletileceğini
belirtiyor. Dönüş değeri olarakda heap'in yeni adresini döndürüyor. Yani sbrk(0) yaparak heap'in lokasyonunu öğrenmek
mümkün.
Ayrıca Linux'da, standart olarak UNIX'de bulunmayan brk() isimli bir sistem çağrısı daha mevcut. Bu çağrı eski UNIX
sbrk() çağrısının assembly davranışı sunuyor. Bu davranış basitçe adresi artırmak yerine, adresi doğrudan ayarlamaktan
geçiyor. sbrk(0)a benzer bir şekilde brk(NULL) yaparak da heap'in adresini almak mümkün.
Hatta çoğu program tam olarak bunu yapıyor, mesela strace ile ls çalıştırmayı deneyin:
root@o101:~# strace ls
execve("/usr/bin/ls", ["ls"], 0x7fffffffe5f0 /* 14 vars */) = 0
brk(NULL) = 0x55555557a000
...
Tabi normalde kendi heap implementasyonu olmayan çoğu program, heap ile bu şekilde etkileşimde bulunmaz. Genel olarak heap'in yönetimi bir dinamik bellek dağıtımcısı'na bırakılır. Bu arkadaş farklı belelk alanları ve algoritmalar kullanarak, heap kullanımını ve yönetimi kolaylaştırır ve optimize eder.
Spesifik olarak bizim incleyeceğimiz olan, ve çoğu GNU/Linux dağıtımında kullanılan GNU C kütüphanesi (glibc) dinamik bellek
yönetimi adına, kullanımı gayet kolay, hepimizin bildiği malloc(), calloc() ve free() gibi fonksiyonlar sunar. Bu fonksiyonları
açıklıyor olmayacağım, eğer ne olduklarını bilmiyorsanız kesinlike README.md dosyasındaki gerekli ön bilgileri
okumadınız demek :)
Her neyse, bu fonksiyonların farklı implementasyonları mevcut, dlmalloc, jemalloc ve de nedmalloc gibi. Ve bu implementasyonlar
farklı projeler tarafından kullanılıyor. glibc ise ptmalloc implementasyonunu kullanıyor ve merak etmeyin az sonra bundan daha detaylı bahsedeceğiz.
Peki neden bu fonksiyonlar bizim umurumuzda olsun ki? Basit, çoğu program bu glibc fonksiyonlarını kullandığından, heap'de karşılacağımız çoğu sorun, bu fonksiyonların yanlış kullanımı, ya da bu fonksiyonlar ile elde edilen heap alanlarının yanlış kullanımı sonucu ortaya çıkar. Heap'de bu şekilde ortaya çıkan bellek sorunlarını kötüye kullanıp programı kontrol etmenin tek yolu, bu fonksiyonların implementasyonlarında kullandığı kişisel veri yapılarını hedef almak olacaktır.
Bu sebepten heap'i exploit edemebilmek adına glibc dinamik bellek dağıtımcısını anlamamız çok önemli. Tabi bu aynı zamanda farklı bellek dağıtımcıları kullanan programların, farklı şekilde ele alınacağı anlamına geliyor. Tam olarak bu sebepten ötürü heap bellek sorunlarını kötüye kullanması, her program ve her mimari için aşağı yukarı aynı çalışan stack'e kıyasla çok daha kompleks olabilir.
Ama her neyse, daha fazla uzatmadan glibc'i incelemeyi başlayalım ne dersiniz?
glibc aktif olarak maintain edilen bir proje olduğundan, ptmalloc implementasyonu da aktif olarak geliştiriliyor. Bu sebepten ötürü,
hem burda, hem de farklı kaynaklarda yayınlanan bilgiler, bunu okudğunuz zamana bağlı olarak eski ve doğru olmayabilir. O yüzden burda
açıkça belirtmek istiyorum, bunu yazdığım sırada tarih 24/12/24, ve en güncel glibc versiyonu 22/07/24'de yayınlanan 2.40. Bizim
kullancağımız ve lab ile beraber gelen glibc kaynağıda bu versiyonu kullanıyor. Ancak ben az sonra detaylı bahsedeceğim üzere,
11/12/24 tarihine kadar bazı önemli patch'leri bu versiyona backportladım. Bu sayede bu kaynak, 02/01/24'de yayınlanması beklenen 2.41
yayınlandığında bile güncel kalabilir (umarım).
Ayrıca açık değilse diye uyarmak istiyorum ki her GNU/Linux dağıtımı aynı glibc versiyonunu kullanmıyor. Ayrıca farklı CTF challenge'ları
da farklı glibc versiyonları kullanabiliyor. O yüzden benim burda eski olduğundan bahsetemeyeceğim teknikleri, başka yerlerde görürseniz
eski olmalarına ve modern glibc versiyonlarında çalışmamalarına rağmen öğrenmek istiyebilirsiniz.
Biz kaynak kodu olarak patchlediğim 2.40 versiyonunu inceleyeceğiz, bunu ev dizininde glibc-2.40 ismi ile bulabilirsiniz. Bu versiyon aynı
zamanda benim eklediğim bazı ek log'lama satırlarına sahip. Uyguladığım tüm patchlerin listesini src/files/glibc-patches
dizininde bulabilirsiniz. Öte yandan sıradaki bölümde ilk heap binary'imizi exploit ederken debian'ın anlık glibc sürümü olan 2.36 versiyonunu
kullanacağız. Merak etmeyin exploitimiz bu iki versiyon ile de sorunsuz çalışacak, ve ben 2.36 da çalışıp, bu patchlediğim versiyonda çalışmayan
bir tekniği gösteriyor ya da kullanıyor olmayacağım.
glibc'nin ptmalloc implementasyonunu açıklamaya başlamadan önce, ilk olarak size verdiğim kaynağı derlemeniz lazım. Bunu nasıl yapacağınız
wiki sayfasında anlatılıyor. Ama ben hızlıca özetliyecek olursam kaynak dizini içinde aşağıdaki
komutları çalıştırmanız yeterli:
mkdir build
cd build
../configure --prefix=/usr
makedaha hızlı bir build için tüm işlemci çekirdeklerini kullanmayı tercih edebilirsiniz:
make -j$(nproc)
Derleme işlemcinize ve RAM'inize bağlı olarak uzun bir zaman alabilir. Derleme sırasında okumaya devam edebilirsiniz.
Glibc'nin ptmalloc implementasyonu malloc/ kaynak dizini altında bulunuyor. Ve de bu wiki sayfasında
güzelce açıklanmış. Ancak ben yine de kendi açıklamamı veriyor olacağım. Tabi malloc/ dizini altında herşeyi okumanız mümkün değil (tabiki ben de okumadım),
bunun yerine ben size işlerin nasıl çalıştığını açıklarken bu dizindeki kaynak kodundan referanslar vereceğim, siz de dilerseniz gidip detaylıca incleyebilirsiniz.
Ayrıca 0x6 dizininde, sırasıyla bakıcağımız bazı örnekler de var.
Artık başlasak iyi olur.
İlk olarak chunk yapısını anlamanız lazım. Heap geniş bir veri alanı olduğundan, glibc bu alanı chunk denilen alanlar ile ele alıyor.
İlk başta sahip olduğumuz tüm heap, tek bir devasa chunk'da yer alıyor. Biz malloc() ile farklı miktarlarda bellek istedikçe, glibc bu
devasa chunk'ı daha küçük chunk'lara bölüyor. Ve siz farklı chunk'ları serbest bıraktıkça ve yeni chunk'lar istedikçe, glibc chunkları
birleştiriyor, bölüyor ve bu şekilde devam ediyor.
Eğer glibcnin sizin istediğiniz belleği tutabilecek bir chunk'ı yoksa, heap'i bahsetiğimiz brk çağrısı ile genişletip, sizin chunk'ınız
için yeni bir alan oluşturuyor.
Yani siz malloc() ve free() kullanırken, aslında bu chunkları kullanıma alıp, serbest bırakıyorsunuz. Bu chunk yapısı şu şekilde:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};Kaynak kodu, yorum satırları ile bu chunk yapısının nasıl kullanıldığını aslında güzel bir şekilde anlatıyor:
malloc_chunk details:
(The following includes lightly edited explanations by Colin Plumb.)
Chunks of memory are maintained using a `boundary tag' method as
described in e.g., Knuth or Standish. (See the paper by Paul
Wilson ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a
survey of such techniques.) Sizes of free chunks are stored both
in the front of each chunk and at the end. This makes
consolidating fragmented chunks into bigger chunks very fast. The
size fields also hold bits representing whether chunks are free or
in use.
An allocated chunk looks like this:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Basitçe açıklamak gerekirse, chunk'ın ait olduğu bellek adresi fdnin offseti pozisyonunda. Yani ilk iki değer
mchunk_prev_size ve mchunk_size (16 byte), chunk'ın header'ı gibi düşünebilirsiniz. Chunk kullanımda ise, yani malloc()
ile kullanıma alınmışsa, veri yapısının geri kalanın bir anlamı yok. Chunk'ın bu header'ının sonu, chunk'ın malloc()
sonucu bize verdiği adres, yani chunk'ın sahip olduğu veri alanın başlangıç noktası.
Yani, siz malloc() çağırdığınızda aldığınız adres, yorumda mem ile ifade edilen "kullanıcı verisini"nin başladığı nokta.
Hemen 16 byte üstünüzde ise mchunk_prev_size ve mchunk_size, yani chunk'ın header'ı var. Zaten bu sebepten ötürü, free()
ile bir chunk'ı serbest bıraktığınızda, boyut belirtmek zorunda olmuyorsunuz. Çünkü free() zaten boyutu header'dan öğreniyor.
Bu header'dan ötürü, her chunk 16 byte hizalı. Ve bu yüzden her chunk'ın boyutu 16'nın katı olmak zorunda. Siz 16 byte'dan
daha az ya da 16'nın katı olmayan bir bellek alanı istesenizde, malloc() bu boyutu en yakın 16'nın katına yuvarlayıp, size o boyuta
sahip bir chunk verecktir.
Chunk kullanımda değil ise, yani malloc() ile kullanıma alınmamışsa ya da free() ile serbest bırakılmışsa, o zaman
chunk yapısının geri kalanı, duruma bağlı olarak, az sonra detaylı bahsedeceğimiz, farklı bir şekilde kullanılıyor.
Şimdi mchunk_prev_size ve mchunk_sizea bir bakalım. Adından da anlayabileceğiniz gibi ilki, önceki chunk'ın boyutunu, ikincisi
şuanki chunk'ın boyutunu ifade ediyor (header dahil). Bu arkadaşlar sayesinde chunk'ın mem adresine ekleme/çıkarma yaparak, önceki/sonraki
chunk'a ilerleyebiliyoruz.
Fakat bu ikisi sadece boyutu tutmuyor. İlk olarak mchunk_size, bu 8 byte'ın ilk 3 biti, aslında yorumda A, M ve P
ile gösterilmiş farklı flagleri tutuyor. Zaten her chunk'ın boyutu 16'nın bir katı olduğundan, ilk 4 bite ihtiyacımız yok, o yüzden bu bir
sorun değil.
Bu flagler yine kaynak kodunda açıklanmış:
/* size field is or'ed with PREV_INUSE when previous adjacent chunk in use */
#define PREV_INUSE 0x1
/* extract inuse bit of previous chunk */
#define prev_inuse(p) ((p)->mchunk_size & PREV_INUSE)
/* size field is or'ed with IS_MMAPPED if the chunk was obtained with mmap() */
#define IS_MMAPPED 0x2
/* check for mmap()'ed chunk */
#define chunk_is_mmapped(p) ((p)->mchunk_size & IS_MMAPPED)
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained
from a non-main arena. This is only set immediately before handing
the chunk to the user, if necessary. */
#define NON_MAIN_ARENA 0x4
/* Check for chunk from main arena. */
#define chunk_main_arena(p) (((p)->mchunk_size & NON_MAIN_ARENA) == 0)
/* Mark a chunk as not being on the main arena. */
#define set_non_main_arena(p) ((p)->mchunk_size |= NON_MAIN_ARENA)Biz sadece ilk flag'i (ilk bit) önemsiyoruz, gerisinin kafanızı karıştırmasına izin vermeyin. Bu ilk flag eğer 1 olarak işaretli ise, önceki chunk
kullanımda demek. Bu da bizi mchunk_prev_sizea getiriyor. İlginç bir şekilde, eğer önceki chunk kullanımda ise, mchunk_prev_size önceki chunk'ın
bellek alanında dahil ediliyor. Bunun amacı, 8 byte için, chunk'a fazladan 7 byte daha eklemeyi önlemek.
Örnek olarak diyelim 17 byte allocate etmek istediniz. Bu durumda bize, 48 byte boyutunda bir chunk lazım (header + 17 + 16'nın katına yuvarlama), ancak
sıradaki chunk'ın ilk 8 byte'ı olan mchunk_prev_sizeda bize ait olduğundan tek bir 32 byte boyutunda chunk ile bu allocation'ı gerçekleştirebiliyoruz.
Aşağıda, wiki sayfasından alınmış, biri kullanımda ve biri serbest olan chunk'ı gösteren iki resim var:


Hadi bu 0x6daki ilk örneğimizde inceleyelim, chunk_data dizininde olan bu örneği make ile derelyip, make run ile çalıştırın:
alloc_size = 1983
(a) malloc = 0x6358639d82a0
(b) malloc = 0x6358639d8a70
a_chunk = 0x6358639d8290 (a-16)
b_chunk = 0x6358639d8a60 (b-16)
a_chunk->mchunk_prev_size = 0
a_chunk->mchunk_size = 2001 (PREV_INUSE)
b_chunk->mchunk_prev_size = 0
b_chunk->mchunk_size = 2001 (PREV_INUSE)
(a) free = 0x6358639d82a0
a_chunk->mchunk_prev_size = 0
a_chunk->mchunk_size = 2001 (PREV_INUSE)
b_chunk->mchunk_prev_size = 2000
b_chunk->mchunk_size = 2000
Bu örnekte, malloc() ile (kesinlikle bir yere referans olmayan) 1983 boyutunda, iki tane chunk (a ve b) allocate ediyoruz.
Hatırlarsanız, bu bize verilen adreslerin 16 byte öncesinde header'larımız yer alıyor, bu header'ların adreslerini alıyoruz. Ardından iki header'ın da mchunk_prev_size ve mchunk_size
değerlerini ekrana basıyoruz.
Bu değerleri incelersek, ilk olarak, iki chunk'ında PREV_INUSE flag'i 1 olarak işaretli. Ayrıca ikisinin de boyutu 2000 byte. Biz 1983 byte istedik, ancak üzerine
header'ı ekleyip (1983 + 16 = 1999), 16'nın katına yuvarlayınca, boyut 2000 olmuş. Bu boyutu aynı zamanda bnin adan hemen sonraki chunk olduğunu doğrulamak
için kullanabiliriz. anın chunk'ına (0x6358639d8290) 2000 eklersek, 0x6358639d8290 + 2000 = 0x6358639d8a60 hesabından, evet, b hemen adan sonra geliyor.
Ki bu gayet mantıklı, çünkü byi, adan hemen sonra allocate ettik. Bu durumda malloc()un sıradaki chunk'ı kullanması gayet mantıklı.
Tabi bu aynı zamanda, eğer ayı serbest bırakırsak, bnin mchunk_prev_sizeı güncellenecek demek. Biz de tam olarak bunu yapıyoruz, ayı serbest bırakıp tekrar
header'ları ekrana bastığımızda, bnin chunk'ı için mchunk_prev_size artık 2000'in değerine sahip, bu da anın boyutu ile uyuşuyor.
Sıradaki örneğimiz ise chunk_overlap, yine aynı komutlar ile derleyip, çalıştırabilirsiniz.
Bu sefer, bahsettiğim mchunk_prev_sizeı, önceki chunk'ın bir parçası olarak kullanma durumunu inceliyor olacağız. Hadi program çıktısına bakalım:
alloc_size = 24
(a) malloc = 0x62b6471152a0
(b) malloc = 0x62b6471152c0
a_chunk = 0x62b647115290 (a-16)
b_chunk = 0x62b6471152b0 (b-16)
a_chunk->mchunk_prev_size = 0x0
a_chunk->mchunk_size = 33 (PREV_INUSE)
b_chunk->mchunk_prev_size = 0x42424242
b_chunk->mchunk_size = 33 (PREV_INUSE)
İki tane 24 byte boyutunda allocation yapıyoruz. 24+16 = 40 olduğuna göre, 16 byte hizalama için bize 8 byte daha gerecek. Ama hatırlarsanız önceki chunk
kullanıldığı durumda, kendisinden sonra gelen chunk'ın mchunk_prev_sizeını veri alanı olarak kullanabiliyor. Bu sebepten ötürü sadece 32 byte olan bir
chunk'a ihtiyacımız var, sonrasında sıradaki chunk'ın mchunk_prev_sizeını bize gereken 40 byte'ın son 8 byte'ı olarak kullanabiliriz. Bu sayede sadece
32 byte chunk'lar kullanarak 40 byte veriyi sığdırmış oluyoruz.
Bunu programın çıktısında görebilirsiniz. Program allocate ettiği a ve b belleklerini 0x42 byte'ı ile dolduruyor. Bu sebepten ötürü adan sonra
gelen bnin mchunk_prev_sizeı a tarafından kullanılıyor ve 0x42424242 değerine sahip.
Başta tüm heap'in devasa bir chunk olarak ele alındığını söylemiştim. Aslında bu chunk'ın bir adı var, "wilderness" yani "yaban" (veya "ıssızlık"). Bu wilderness
dizinindeki örnek ile wildernessın biz daha fazla bellek istedikçe nasıl küçüldüğünü, ve isteklerimiz için yeteri kadar heap alanı kalmadığında brk()
ile glibcnin nasıl wildernessı genişletiğine bakacağız.
Yine önceki komutlar ile örneği derleyip çalıştırabilirsiniz:
malloc(16) = 0x56e9bdbfe2a0
wilderness_chunk = 0x56e9bdbfe2b0
wilderness_chunk->mchunk_size = 134481
malloc(16) = 0x56e9bdbfe2c0
wilderness_chunk = 0x56e9bdbfe2d0
wilderness_chunk->mchunk_size = 134449
malloc(4080) = 0x56e9bdbfe2e0
wilderness_chunk = 0x56e9bdbff2d0
wilderness_chunk->mchunk_size = 130353
malloc(4080) = 0x56e9bdbff2e0
wilderness_chunk = 0x56e9bdc002d0
wilderness_chunk->mchunk_size = 126257
...
malloc(4080) = 0x56e9bdc1c2e0
wilderness_chunk = 0x56e9bdc1d2d0
wilderness_chunk->mchunk_size = 7473
malloc(4080) = 0x56e9bdc1d2e0
wilderness_chunk = 0x56e9bdc1e2d0
wilderness_chunk->mchunk_size = 3377
malloc(4080) = 0x56e9bdc1e2e0
wilderness_chunk = 0x56e9bdc1f2d0
wilderness_chunk->mchunk_size = 134449
Çıktı uzun olduğundan çoğunluğunu kestim. Ancak gördüğünüz gibi, wilderness chunk'ı en son allocate ettiğimiz chunk'dan hemen sonra geliyor. Ve biz daha fazla
bellek istedikçe wilderness chunk'ı daha küçük chunklara bölündüğünden giderek küçülüyor ve küçülüyor. En son, wilderness'da sadece 3377 byte kalmışken, 4080 byte'lık
bir allocation istiyoruz. Artık yeterli alanı kalmadığından, glibc bu noktada brk() çağrısı ile heap'i genişletiyor, bu sayede wilderness'da genişliyor. Ve bunu
malloc()dan sonra, wilderness'ın artan mchunk_size alanında görüyoruz.
Eğer strace ile programı tekrar çalıştırırsak, brk() gerçekten de bu noktada çalıştırıldığını doğrulayabiliriz:
...
write(1, "malloc(4080) = 0x635c53e232e0\n", 30malloc(4080) = 0x635c53e232e0
) = 30
write(1, "wilderness_chunk = 0x635c53e242d"..., 34wilderness_chunk = 0x635c53e242d0
) = 34
write(1, "wilderness_chunk->mchunk_size = "..., 37wilderness_chunk->mchunk_size = 7473
) = 37
write(1, "malloc(4080) = 0x635c53e242e0\n", 30malloc(4080) = 0x635c53e242e0
) = 30
write(1, "wilderness_chunk = 0x635c53e252d"..., 34wilderness_chunk = 0x635c53e252d0
) = 34
write(1, "wilderness_chunk->mchunk_size = "..., 37wilderness_chunk->mchunk_size = 3377
) = 37
brk(0x635c53e47000) = 0x635c53e47000
write(1, "malloc(4080) = 0x635c53e252e0\n", 30malloc(4080) = 0x635c53e252e0
) = 30
write(1, "wilderness_chunk = 0x635c53e262d"..., 34wilderness_chunk = 0x635c53e262d0
) = 34
write(1, "wilderness_chunk->mchunk_size = "..., 39wilderness_chunk->mchunk_size = 134449
) = 39
exit_group(0) = ?
+++ exited with 0 +++
Gördüğünüz gibi, tam olarak dediğimiz noktada glibc wilderness'ı genişletiyor.
Bazı durumlarda, serbest bırakılan bazı chunk'lar doğrudan serbest kalmıyor. Özellikle küçük chunk'lar, tekrardan kullanılmak istendiğinde bulunmaları zaman aldığından, tcache yani "thread (local) cache" isimli bir cache yapısına yerleştiriliyor. Bu sayede, tekrar küçük bir chunk'a ihtiyacımız olduğunda, tcache içinde hızlıca bu chunk'ı bulabiliyoruz.
tcache yapısı, özünde seperate chaining kullanan bir hash table. Aranızda veri yapıları 101 görmemiş olanlar için basitçe içinde listeler olan bir liste. Hadi veri yapısını inceleyelim:
/* We overlay this structure on the user-data portion of a chunk when
the chunk is stored in the per-thread cache. */
typedef struct tcache_entry
{
struct tcache_entry *next;
/* This field exists to detect double frees. */
uintptr_t key;
} tcache_entry;
/* There is one of these for each thread, which contains the
per-thread cache (hence "tcache_perthread_struct"). Keeping
overall size low is mildly important. Note that COUNTS and ENTRIES
are redundant (we could have just counted the linked list each
time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;Burada her entry'nin adresi, direk chunk'ın kendi adresi. Ve her chunk'ın içine 16 byte boyutunda iki değer yerleştiriliyor. İlk değer (next)
sıradaki chunk'a işaret ediyor. İkinci değere ise az sonra geleceğiz.
Yani, tcache_perthread_structdaki entries listesindeki her bir entry, bir linked list'in ilk elemanı, ve bu chunk'larden oluşan linked listelerine bin deniyor.
Ve dediğim gibi, bu bir hash table olduğundan bu entries listesine index'lemek için bize bir hash fonksiyonu lazım değil mi? Eh, bu fonksiyon da chunk'ın boyutu
üzerine çalışıyor. Bu demek oluyor ki, her bir index, sadece belirli bir boyuta ait chunk'ları tutuyor. Aynı hash fonksiyonu, aynı zamanda counts listesine indexleyip,
entries listesinde aynı indexde olan chunk sayısını güncellemede kullanılıyor.
Hadi şimdi tcache'ye ekleme yapmakta görevli tcache_put() fonksiyonunu inceleyelim:
/* Caller must ensure that we know tc_idx is valid and there's room
for more chunks. */
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
/* Mark this chunk as "in the tcache" so the test in _int_free will
detect a double free. */
e->key = tcache_key;
e->next = PROTECT_PTR (&e->next, tcache->entries[tc_idx]);
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
printf("\x1b[36m##=========== %s ===========\n", __func__);
printf("|| index = %ld count = %u\n", tc_idx, tcache->counts[tc_idx]);
printf("|| entry = %p\n", e);
printf("|| entry->key = 0x%lx\n", e->key);
printf("|| entry->next = %p (%p)\n", e->next, REVEAL_PTR(e->next));
printf("##=========== %s ===========\x1b[0m\n", __func__);
}Gördüğünüz gibi ben buraya bir kaç işimize gelcek printf() çıktısı ekledim, aldrış etmeyin. Burda ilgi çekici iki şey. tcache_key ve
PROTECT_PTR. tcache_key daha sonra bahsedeceğimizi söylediğim key değeri için kullanılıyor. PROTECT_PTR ise nextin değerini
belirtmek için kullanılıyor. next burada, listenin başına işaret edilecek şekilde değiştiriliyor, yani yeni eklenen tcache entry'leri bin'in
sonuna değil, başına ekleniyor.
Ancak bu PROTECT_PTR ne olaki? Aslında ismi gayet iyi açıklıyor, "pointer koruyucu". Basitçe pointer'ın pozisyonunu, pointer'ın değeri ile XOR'layarak,
pointer'ın değerinin, pointer'ın pozisyonun bilinmeden değiştirilmesini engelliyor. Asıl pointer değerine erişmek için de REVEAL_PTR macrosu kullanılıyor.
Bu macro'da basitçe aynı şeyi tersten yapıyor:
/* Safe-Linking:
Use randomness from ASLR (mmap_base) to protect single-linked lists
of Fast-Bins and TCache. That is, mask the "next" pointers of the
lists' chunks, and also perform allocation alignment checks on them.
This mechanism reduces the risk of pointer hijacking, as was done with
Safe-Unlinking in the double-linked lists of Small-Bins.
It assumes a minimum page size of 4096 bytes (12 bits). Systems with
larger pages provide less entropy, although the pointer mangling
still works. */
#define PROTECT_PTR(pos, ptr) \
((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
#define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)Yorumda da belirtildiği gibi, bu, pointer'ın pozisyonunun ASLR açık olduğu sürece rastgele olduğu gerçeğini kullanarak bir saldırganın kolayca adresi değiştirmesini önlemeye çalışıyor. Bu tekniğe safe-linking deniyor.
Güzel, peki bu listelere indexlemek için kullanılan hash fonksiyonu nasıl çalışıyor? Eh, bunu anlamak için tcache_index örneğini kullanabiliriz. Bu örnek
aynı zamanda kaynak koduna yerleştirdiğim ve az önce gösterdiğim tcache_put() loglarını kullanılıyor. Yani tcache'ye bir şey eklenince ekrana basıyor olacağız.
Her neyse, hadi çıktıyı inceleyelim:
(a) malloc(16) = 0x558add6712a0
(b) malloc(16) = 0x558add6722d0
##=========== tcache_put ===========
|| index = 0 count = 1
|| entry = 0x558add6712a0
|| entry->key = 0xc1cbe2c9dcc038ef
|| entry->next = 0x558add671 ((nil))
##=========== tcache_put ===========
(a) free = 0x558add6712a0
##=========== tcache_put ===========
|| index = 0 count = 2
|| entry = 0x558add6722d0
|| entry->key = 0xc1cbe2c9dcc038ef
|| entry->next = 0x558f85cac4d2 (0x558add6712a0)
##=========== tcache_put ===========
(b) free = 0x558add6722d0
(a) malloc(32) = 0x558add6722f0
(b) malloc(32) = 0x558add672320
##=========== tcache_put ===========
|| index = 1 count = 1
|| entry = 0x558add6722f0
|| entry->key = 0xc1cbe2c9dcc038ef
|| entry->next = 0x558add672 ((nil))
##=========== tcache_put ===========
(a) free = 0x558add6722f0
##=========== tcache_put ===========
|| index = 1 count = 2
|| entry = 0x558add672320
|| entry->key = 0xc1cbe2c9dcc038ef
|| entry->next = 0x558f85caf482 (0x558add6722f0)
##=========== tcache_put ===========
(b) free = 0x558add672320
...
Gördüğünüz gibi, giderek artan boyutta bellek alanları isteyip sonra bu alanları serbest bırakıyoruz. Her farklı boyut için 2 adet alan istiyoruz. Ve
ilk alanı serbest bıraktığımızda, indexlenip, listeye ilk girdi olarak ekleniyor. İkinci alanı serbest bıraktığımızda, aynı şekilde indexlenip, listeye ekleniyor.
Ve farketiyseniz listenin başına ekleniyor. Parantez içinde verilen entry->next adresi ile bunu doğrulayabilirsiniz.
Çıktının sonuna geldiğimizde, bir noktadan sonra tcache'nin kullanımının bırakıldığını görüyoruz:
(a) malloc(1024) = 0x5bf1dd8e1690
(b) malloc(1024) = 0x5bf1dd8e1aa0
##=========== tcache_put ===========
|| index = 63 count = 1
|| entry = 0x5bf1dd8e1690
|| entry->key = 0xac3430c1c270e9bc
|| entry->next = 0x5bf1dd8e1 ((nil))
##=========== tcache_put ===========
(a) free = 0x5bf1dd8e1690
##=========== tcache_put ===========
|| index = 63 count = 2
|| entry = 0x5bf1dd8e1aa0
|| entry->key = 0xac3430c1c270e9bc
|| entry->next = 0x5bf46293ce71 (0x5bf1dd8e1690)
##=========== tcache_put ===========
(b) free = 0x5bf1dd8e1aa0
(a) malloc(1040) = 0x5bf1dd8e1eb0
(b) malloc(1040) = 0x5bf1dd8e22d0
(a) free = 0x5bf1dd8e1eb0
(b) free = 0x5bf1dd8e22d0
(a) malloc(1056) = 0x5bf1dd8e1eb0
(b) malloc(1056) = 0x5bf1dd8e22e0
(a) free = 0x5bf1dd8e1eb0
(b) free = 0x5bf1dd8e22e0
...
Bu gayet mantıklı çünkü tcache listelerinin, gördüğümüz gibi TCACHE_MAX_BINS olarak belirtilen bir boyutu var:
/* We want 64 entries. This is an arbitrary limit, which tunables can reduce. */
# define TCACHE_MAX_BINS 64Ve bu sebepten ötürü, index = 63 olduktan sonra tcache'e ekleme yapmayı bırakıyoruz, çünkü hash fonksiyonu (her ne ise) artık liste boyutunun
dışında çıktılar veriyor demek.
Ama bu hala hash fonksiyonunu tam olarak açıklamıyor.
Bu asıl index almak için kullanılan hash fonksiyonu, birçok farklı macro'yu kullanıyor, ben de hepsini bu örnekte bir araya getirdim, bu sayede istediğimiz boyutun index'ini hesaplayabiliriz ve farklı index'lerin boyut limitlerini görebiliriz.
Bu örneği make ile derleyip, make run ile çalıştırırsak, bizim için 42'nin index'ini hesaplayacaktır:
index = 2 (size = 42)
index = 0 max size = 24
index = 1 max size = 40
>>> index = 2 max size = 56
index = 3 max size = 72
index = 4 max size = 88
...
index = 59 max size = 968
index = 60 max size = 984
index = 61 max size = 1000
index = 62 max size = 1016
index = 63 max size = 1032
Ve bize farklı index'lerin ve maksimum boyutlarının uzun bir listesini de sunuyor. Ve gördüğün gibi ilk index 24 byte'dan başlıyor. Geri kalanı
16'lık bir şekilde artıyor. Burada görüyoruz ki, 42 boyutuna sahip bir chunk, tcache'de 2. indexe yerleştirilirmiş. Aynı zamanda tcache'nin kabül ettiği
maksimum boyutun 1032 olduğunu da görüyoruz. Yani boyutu 1032'den büyük hiçbir chunk serbest bırakıldığında tcache'ye kesin olarak girmeyecektir.
Yani geri kalan tüm boyutlar her zaman tcache'ye mi ekleniyor? Hayır, tcache'nin bu bin'leri için bir limit var, her listede sadece 7 chunk olması mümkün:
/* This is another arbitrary limit, which tunables can change. Each
tcache bin will hold at most this number of chunks. */
# define TCACHE_FILL_COUNT 7
Yani eğer bir 10 tane 16 byte boyutuna sahip allocation yapıp, 10 tane 32 byte chunk alırsak, bunların hepsini art arda serbest bıraktığımızda, ilk 7 chunk index 1'deki linked listeyi, yani bin'i dolduracağından geriye kalan 3 entry tcache'e eklenmiyecektir.
Double-free, çoğunuz bildiği gibi bir bellek alanını iki kere free()leyince ortaya çıkıyor. tcache entry'leri bu bellek sorununu önlemek için key
değerine sahip. Hafınızı yenilemek adına tcache_puta tekrar bakalım:
/* Caller must ensure that we know tc_idx is valid and there's room
for more chunks. */
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
/* Mark this chunk as "in the tcache" so the test in _int_free will
detect a double free. */
e->key = tcache_key;```
...Gördüğünüz gibi keye tcache_key değeri veriliyor. Bu değer rastgele olarak üretiliyor:
/* The value of tcache_key does not really have to be a cryptographically
secure random number. It only needs to be arbitrary enough so that it does
not collide with values present in applications. If a collision does happen
consistently enough, it could cause a degradation in performance since the
entire list is checked to check if the block indeed has been freed the
second time. The odds of this happening are exceedingly low though, about 1
in 2^wordsize. There is probably a higher chance of the performance
degradation being due to a double free where the first free happened in a
different thread; that's a case this check does not cover. */
static void
tcache_key_initialize (void)
{
/* We need to use the _nostatus version here, see BZ 29624. */
if (__getrandom_nocancel_nostatus (&tcache_key, sizeof(tcache_key),
GRND_NONBLOCK)
!= sizeof (tcache_key))
{
tcache_key = random_bits ();
#if __WORDSIZE == 64
tcache_key = (tcache_key << 32) | random_bits ();
#endif
}
}Bu değer free() tarafından chunk tekrardan serbest bırakılmadan kontrol ediliyor, bu sayede chunk'ın tekrardan serbest bırakılıp potansiyel bir bellek
sorununu önlüyor:
/* Try to free chunk to the tcache, if success return true.
Caller must ensure that chunk and size are valid. */
static inline bool
tcache_free (mchunkptr p, INTERNAL_SIZE_T size)
{
bool done = false;
size_t tc_idx = csize2tidx (size);
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100%
trust it (it also matches random payload data at a 1 in
2^<size_t> chance), so verify it's not an unlikely
coincidence before aborting. */
if (__glibc_unlikely (e->key == tcache_key))
tcache_double_free_verify (e, tc_idx);
...Ve bu değeri korumak adına tcache_get_n() ile bir chunk tcache'den alınırken, bu değer sıfırlanıyor:
/* Caller must ensure that we know tc_idx is valid and there's
available chunks to remove. Removes chunk from the middle of the
list. */
static __always_inline void *
tcache_get_n (size_t tc_idx, tcache_entry **ep)
{
tcache_entry *e;
if (ep == &(tcache->entries[tc_idx]))
e = *ep;
else
e = REVEAL_PTR (*ep);
if (__glibc_unlikely (!aligned_OK (e)))
malloc_printerr ("malloc(): unaligned tcache chunk detected");
if (ep == &(tcache->entries[tc_idx]))
*ep = REVEAL_PTR (e->next);
else
*ep = PROTECT_PTR (ep, REVEAL_PTR (e->next));
--(tcache->counts[tc_idx]);
e->key = 0;
return (void *) e;
}Tabi yorumlarda belirtildiği gibi, bu değerin şans eseri eşleşmesi de mümkün, belki de programın chunk'a yazdığı değer tcache_key ile aynı idi. Bu her ne kadar
düşük bir ihtimal de olsa (1/2^64, 1/18446744073709551616), bu sorunu önlemek amacı ile tcache_double_free_verify() fonksiyonu ile tüm tcache bin'ini kontrol edilip
gerçekten de double free'nin söz konusu olup olmadığı doğrulanıyor:
/* Verify if the suspicious tcache_entry is double free.
It's not expected to execute very often, mark it as noinline. */
static __attribute__ ((noinline)) void
tcache_double_free_verify (tcache_entry *e, size_t tc_idx)
{
tcache_entry *tmp;
size_t cnt = 0;
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
for (tmp = tcache->entries[tc_idx];
tmp;
tmp = REVEAL_PTR (tmp->next), ++cnt)
{
if (cnt >= mp_.tcache_count)
malloc_printerr ("free(): too many chunks detected in tcache");
if (__glibc_unlikely (!aligned_OK (tmp)))
malloc_printerr ("free(): unaligned chunk detected in tcache 2");
if (tmp == e)
malloc_printerr ("free(): double free detected in tcache 2");
/* If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort. */
}
}Bu noktada eğer gerçekten double free söz konusu ise, programın malloc_printerr ile sonlandırılacaktır:
static void
malloc_printerr (const char *str)
{
#if IS_IN (libc)
__libc_message ("%s\n", str);
#else
__libc_fatal (str);
#endif
__builtin_unreachable ();
}Yani tcache'ye serbest bırakılan bir değeri tekrar serbest bırakırsak, free(): double free detected in tcache 2 hata mesajı ile program sonlanacak. Peki
program herhangi bir sebepten ötürü sonlanmadı diyelim. Bu durumda ne olacağını tahmin edebiliyor musunuz? Evet potansiyel olarak bir segmentasyon hatası alabiliriz,
ancak tcache'de alan varsa, free() özünde bu bellek alanı ile segmentasyon hatasına sebep olabilecek birşey yapmıyor aslında. Sadece alanı tcache'ye ekliyor.
Bu ne demek oluyor? Yani aynı chunk'ı tcache'ye iki kere ekleyebiliriz.
Bu sayede malloc() sıradaki allocation için tcache'i baktığında, bizim double free'lediğimiz chunk'ın iki tane girdisi olduğundan (eğer aynı boyutu allocation yapırsak)
bize aynı adresi iki kere döndürecektir.
Fakat double free yapılmasını nasıl sağlayabiliriz? key değeri bunu önlediğinden, bu yapmanın tek yolu aynı zamanda bir use-after-free (UAF) kullanmak olacaktır. Bildiğiniz gibi
UAF bir bellek alanın serbest bırakıldıktan sonra kullanılması durumunda ortaya çıkıyor. Eğer bir UAF söz konusu ise entry'nin keyini modifiye edip, double free check'ini bypass
edebiliriz.
Bu örnekte tam olarak bunu yapacağız. tcache_doublefree dizinindeki örneği make ile derleyip, make run ile çalıştırabilirsiniz:
(a) malloc = 0x5851ae58a2a0
##=========== tcache_put ===========
|| index = 0 count = 1
|| entry = 0x5851ae58a2a0
|| entry->key = 0xa180c948aa850517
|| entry->next = 0x5851ae58a ((nil))
##=========== tcache_put ===========
(a) free = 0x5851ae58a2a0
a->key = 0xa180c948aa850517
a->key = 0xdeadbeef
##=========== tcache_put ===========
|| index = 0 count = 2
|| entry = 0x5851ae58a2a0
|| entry->key = 0xa180c948aa850517
|| entry->next = 0x58542b42472a (0x5851ae58a2a0)
##=========== tcache_put ===========
(a) free = 0x5851ae58a2a0
malloc = 0x5851ae58a2a0
malloc = 0x5851ae58a2a0
malloc = 0x5851ae58a6d0
Gördüğünüz gibi önce ayı allocate ettikten sonra free()liyoruz ve yeteri kadar küçük olduğundan tcache'ye yerleştiriliyor. Ardından key değerini modifiye ediyoruz. Tekrardan
free()yi çağırdığımızda, bu sayede double free check'ini bypass etmiş oluyoruz. Ve a bir kere daha tcache'ye yerleştiriliyor. Artık tcache'de aynı chunk iki kere mevcut. Sonra
tekrar malloc() ile bellek alanı istediğimizde, aynı free()değimiz chunk, bize iki kere art arda veriliyor.
Sonrasında gerçekleştirdiğimiz malloc()un da aynı chunk'ı döndürmesini bekleyebilirsiniz. Sonuçta şuan tcache bin'inin ilk index'i 0x5851ae58a2a0e işaret ediyor değil mi?
Evet ama hatırlarsanız tcahce bin'lerinin boyutu counts listesinde tutuluyor. Şuan bu bin'in boyutu 0 olduğundan, malloc(), tcache'i kullanmıyor ve doğrudan yeni bir chunk
aramaya gidiyor.
Az önce UAF kullanarak, key değiştirip double free gerçekleştirmenin mümkün olduğunu gördük. Peki next değerine ne dersiniz? next değerini değiştirerek tcache listesini
zehirlememiz mümkün mü? Neden olmasın!
Bunun için tcache_poison dizinindeki örneğe bakıyor olacağız. Bu örneği de aynı şekilde make ile inşa edip make run ile çalıştırabilirsiniz:
poison_buffer = 0x7fff5d5cb530
(a) malloc = 0x5d65044216b0
(b) malloc = 0x5d65044216d0
##=========== tcache_put ===========
|| index = 0 count = 1
|| entry = 0x5d65044216b0
|| entry->key = 0xc02bf051bb5c4d76
|| entry->next = 0x5d6504421 ((nil))
##=========== tcache_put ===========
(a) free = 0x5d65044216b0
##=========== tcache_put ===========
|| index = 0 count = 2
|| entry = 0x5d65044216d0
|| entry->key = 0xc02bf051bb5c4d76
|| entry->next = 0x5d60d2125291 (0x5d65044216b0)
##=========== tcache_put ===========
(b) free = 0x5d65044216d0
b->next = 0x5d60d2125291 (0x5d65044216b0)
b->next = 0x7ffa8b0cf111 (0x7fff5d5cb530)
malloc = 0x5d65044216d0
malloc = 0x7fff5d5cb530
İlk olarak iki chunk allocate ediyoruz. Ardından ikisini de free()liyoruz. İkisi de yeterince küçük olduğundan doğruca tcache'e yerleşiyor. Önce ayı free()lediğimiz için
b->next doğrudan aya işaret ediyor. Ardından b->nexti, posion_buffer adı verdiğimiz, 16 byte hizalı bir stack buffer'ına işaret edicek şekilde değiştiriyoruz. Ardından
tekrar malloc() ile allocation yaptığımızda ilk olarak b chunk'ı alıyoruz. Şimdi index 0 bin'ini bizim stack buffer'ımıza işaret ediyoruz. O yüzden tekrar aynı boyuta bir allocation
yaptığımıza stack adresimi elde ediyoruz.
Bu bizim için önemli, çünkü eğer bir heap overflow (OOB write) söz konusu ise, ve tcache'i zehirlememiz mümkün ise malloc()un bir stack adresi döndürmesini sağlayarak heap overflow'u
stack overflow'a çevirebiliriz.
tcache, şuan bahsetiğimiz ilk bin yapısını kullanan elemandı. Fakat tcache özünde chunk'ların doğdrudan free() ile serbest bırakılmasını önleyen, küçük bir optimizasyon
amaçlı kullanılan veri yapısı. Ve tcache bin'leri kendilerine ait chunk boyutu için dolu olduklarında, ya da geniş chunk'lar kullandığımızda kullanılmıyor. Bu durumda chunk'lar
doğrudan serbest bıraklıyor.
Ancak serbest chunk'ları hala uzun bir chunk listesinde aramak, çok ideal bir yöntem değil. Bu sepebten ötürü, serbest bırakılan chunk'lar, serbest bırakıldıktan sonra farklı bin'ler tarafından takip ediliyor. Şuan bu binler arasından bizim ilgilendiğimiz, fastbin'ler.
Fastbin'ler basitçe küçük serbest chunkların tutulduğu bir linked list. Ne kadar küçük derseniz:
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4)size_tnin boyutu 64 bit'de bir long, yani 8 byte, bu da demek oluyor ki 160 byte ve daha küçük chunk'lar fastbin'ler tarafından kullanılıyor. Fakat hatırlarsanız,
1032 tcache için maksimum boyut. Bu demek oluyor ki, fastbin verilen chunk'ın tcache bin'i dolu olmadıkça kullanılmıyor.
Peki kullanım durumunda, bu kullanım nasıl sağlanıyor? Bunların tcache girdileri gibi kendisine ait bir yapısı yok. Çünkü bu bir cache değil, bu chunk'lar gerçekten de serbest bırakılıyor. O yüzden chunk yapısını kullanabiliriz. Bu yapıyı hemen size tekrar bir hatırlatıyım:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
fastbin özünde tcache binleri gibi bir singly-linked list kullandığından, bunu fd pointerı aracılığı ile yapıyor.
Fastbin'ler, ve tıpkı tcache entry'leri gibi bir çeşit seperate chaining kullanan hash tabloları, kendi index fonksiyonu mevcut:
/* offset 2 to use otherwise unindexable first 2 bins */
#define fastbin_index(sz) \
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
/* The maximum fastbin request size we support */
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4)
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)64 bit sistemlerde, NFASTBINS değeri 10 olarak hesaplanıyor. Yani 10 tane fastbin listesi mevcut, ve her listeye chunk'ınızın boyutu
üzerinden, fastbin_index aracılığı ile indexliyorsunuz.
Ve yine tcache'ye benzer bir şekilde, yeni chunklar doğrudan fastbin'lerin başına ekleniyor:
...
atomic_store_relaxed (&av->have_fastchunks, true);
unsigned int idx = fastbin_index(size);
fb = &fastbin (av, idx);
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
...Bu örnek ile, fastbin'lerin, fdyi nasıl kullandığını göreceğiz. fastbin dizinindeki örneği, make ile derleyip, make run ile çalıştırabiliriz:
malloc = 0x5da52edb62a0
malloc = 0x5da52edb62c0
malloc = 0x5da52edb62e0
malloc = 0x5da52edb6300
malloc = 0x5da52edb6320
malloc = 0x5da52edb6340
malloc = 0x5da52edb6360
(a) malloc = 0x5da52edb6380
(b) malloc = 0x5da52edb63a0
##=========== tcache_put ===========
|| index = 0 count = 1
|| entry = 0x5da52edb62a0
|| entry->key = 0x2cd3169ca91a402b
|| entry->next = 0x5da52edb6 ((nil))
##=========== tcache_put ===========
free = 0x5da52edb62a0
##=========== tcache_put ===========
|| index = 0 count = 2
|| entry = 0x5da52edb62c0
|| entry->key = 0x2cd3169ca91a402b
|| entry->next = 0x5da0f4898f16 (0x5da52edb62a0)
##=========== tcache_put ===========
free = 0x5da52edb62c0
##=========== tcache_put ===========
|| index = 0 count = 3
|| entry = 0x5da52edb62e0
|| entry->key = 0x2cd3169ca91a402b
|| entry->next = 0x5da0f4898f76 (0x5da52edb62c0)
##=========== tcache_put ===========
free = 0x5da52edb62e0
##=========== tcache_put ===========
|| index = 0 count = 4
|| entry = 0x5da52edb6300
|| entry->key = 0x2cd3169ca91a402b
|| entry->next = 0x5da0f4898f56 (0x5da52edb62e0)
##=========== tcache_put ===========
free = 0x5da52edb6300
##=========== tcache_put ===========
|| index = 0 count = 5
|| entry = 0x5da52edb6320
|| entry->key = 0x2cd3169ca91a402b
|| entry->next = 0x5da0f4898eb6 (0x5da52edb6300)
##=========== tcache_put ===========
free = 0x5da52edb6320
##=========== tcache_put ===========
|| index = 0 count = 6
|| entry = 0x5da52edb6340
|| entry->key = 0x2cd3169ca91a402b
|| entry->next = 0x5da0f4898e96 (0x5da52edb6320)
##=========== tcache_put ===========
free = 0x5da52edb6340
##=========== tcache_put ===========
|| index = 0 count = 7
|| entry = 0x5da52edb6360
|| entry->key = 0x2cd3169ca91a402b
|| entry->next = 0x5da0f4898ef6 (0x5da52edb6340)
##=========== tcache_put ===========
free = 0x5da52edb6360
(b) free = 0x5da52edb63a0
b_chunk = 0x5da52edb6390 (b-16)
b_chunk->fd = 0x5da52edb6 ((nil))
b_chunk->bk = 0x4242424242424242
(a) free = 0x5da52edb6380
a_chunk = 0x5da52edb6370 (a-16)
a_chunk->fd = 0x5da0f4898e26 (0x5da52edb6390)
a_chunk->bk = 0x4242424242424242
b_chunk = 0x5da52edb6390 (b-16)
b_chunk->fd = 0x5da52edb6 ((nil))
b_chunk->bk = 0x4242424242424242
Biraz uzun bir çıktı biliyorum. Fakat anlaması gayet basit, ilk olarak 7 adet chunk allocate ediyoruz, ve ek olarak a ve b olarak isimlendirdiğimiz iki chunk daha
allocate ediyoruz (ve bu bellek alanlanlarını 0x42 ile dolduruyoruz). Ardından allocate ettiğimiz 7 chunk'ı serbest bırakarak (hatırlarsanız tcache'de bin boyutu 7)
tcache'in index 0 bin'ini tamamı ile dolduruyoruz.
Bu demek oluyor ki, sırada serbest bırakacağımız bin'ler, doğrudan serbest kalıp fastbin'lerden birine yerleşecek. İlk olarak byi serbest bırakıyoruz ve gördüğünüz gibi
bnin chunk'ının fd'si NULL olarak güncelleniyor. Ardından ayı serbest bıraktığımızda, a artık aynı fastbin'in başına eklendiğinden, a chunk'ının fd'si,
artık b chunk'ına işaret ediyor.
Hadi sıradaki bölüme geçmeden, şuana kadar öğrendiğimiz şeyleri hızlıca bir özetleyelim:
- glibc, heap alanını chunk denilen yapılarda barındıyor, heap ilk başta wilderness isimli tek büyük bir chunk'dan ibaret, ve biz
malloc()çağrılarında bulundukça bu alan daha küçük chunklara bölünüyor. - Biz daha fazla chunk allocate ettikçe, chunklar glibc tarafından bölünüyor ve birleştiriliyor
free()ile serbest bıraktığımız 1032 byte'dan küçük chunklar, doğrudan serbest bırakılmak yerinde, gerekli alan varsa, tcache isimli bir listeye yerleştiriliyor- Eğer tcache'de gerekli alan yoksa, ya da chunk'lar tcache için çok büyükse, fastbin isimli başka bir listeye yerleştiriliyor
Şimdilik bu kadar, daha sonraki bölümlerde, gerektikçe glibc'nin malloc() implementasyonu hakkındaki bilgimizi artıyor olacağız.