You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
The VC-Dimension (named after Vapnik and Chervonenkis) is a measure of complexity for a given hypothesis class. The motivation is as follows: finiteness of a hypothesis class implies PAC-learnability, and the sample complexity depends on the size of the class. However, there are also infinite hypothesis classes which are PAC-learnable. Consider for example the class of threshold functions over the real numbers, $\mathcal{H} = \lbrace h_{a} \rbrace$ where
$h_{a}(x) = 1$ if $a<0$, and $h_{a}(x) = 0$, otherwise. This hypothesis class is PAC-learnable with sample complexity $m(\epsilon,\delta) \leq \lceil \log(2/\delta)/\epsilon \rceil.$
So finiteness is sufficient but not necessary for learnability. To define a more useful measure of complexity, we first need some other definitions.
Restriction of a hypothesis class and shattering sets
We define the Restriction of$\mathcal{H}$to$C = \lbrace c_{1},...,c_{m} \rbrace\subset \mathcal{X}$ as the set of functions from $C$ to $\lbrace 0,1 \rbrace$ that can be derived from $\mathcal{H}$ (i.e. that correspond to a hypothesis in our class). If we describe each function from $C$ to $\lbrace 0,1 \rbrace$ as a vector in $\lbrace 0,1 \rbrace^{|C|}$, we can formally write this as
If $\mathcal{H}_{C}$ is the set of all functions from $C$ to $\lbrace 0,1 \rbrace$ (i.e. $|\mathcal{H}_{C}| = 2^{|C|}$), we say that $\mathcal{H}$shatters$C$.
So $\mathcal{H}$ shatters a set $C$ if every possible labelling (with the two labels $0$ and $1$) can be described by a hypothesis in $\mathcal{H}$.
The VC-Dimension
Now we can define the VC-Dimension. The VC-Dimension of a hypothesis class $\mathcal{H}$, denoted by VCdim$(\mathcal{H})$, is the size of a largest set $C\subset \mathcal{X}$ that is shattered by $\mathcal{H}$.
The motivation behind this definition is as follows. The No-Free-Lunch Theorem effectively states that the set of all functions from a domain to $\lbrace 0,1 \rbrace$ is not PAC-learnable. However, the proof of this statement only works because we are considering all possible functions. So it is a reasonable assumption that restricting ourselves might actually be an advantage.
Note that an infinite VC-Dimension implies non-learnability: for each set of size $m$ there is a set $C\subset \mathcal{X}$ of size $2m$ that is shattered by our hypothesis class. So the restriction of the hypothesis class to $C$ is the set of all functions from $C$ to $\lbrace 0,1 \rbrace$ which, by the No-Free-Lunch Theorem, implies non-learnability.
Example
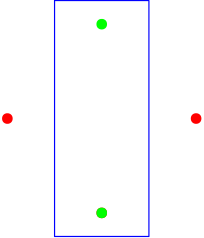
To illustrate the concept of the VC-Dimension, consider the following example. As hypothesis class, we choose the set of all axis-aligned rectangles in the Euclidean plane. If we want to show that a certain number $d$ is indeed the VC-Dimension of a hypothesis class, we need to show two things: VCdim($\mathcal{H}$)$\geq d$ and VCdim($\mathcal{H}$)$ < d+1$.
In this case, VCdim($\mathcal{H}$) = 4.
For the first inequality, we simply need to find one set of 4 points that is shattered by axis-aligned rectangles. We consider 4 equidistant points on a circle.
It is easy to see that any partition of the 4 points into positive (green) and negative (red) can be represented by some axis-aligned rectangle.
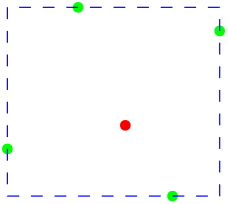
To show that the VC-Dimension is strictly less than 5, we have to show that no set of size 5 is shattered. For this purpose, consider an arbitraty set of 5 points and their bounding box (indicated by the dashed blue rectangle below). There has to be at least one point inside the bounding box (or on one side of the box). Now, if we label the other 4 points positive and the fifth negative, each axis-aligned rectangle containing all positive points also has to contain the negative point. Therefore, no set of size 5 is shattered by $\mathcal{H}$.
The Fundamental Theorem of Statistical Learning
The main reason why studying the VC-Dimension is of interest to us is the so-called Fundamental Theorem of Statistical Learning. It establishes a direct connection between the VC-Dimension and the PAC learnability of a concept class.
Fundamental Theorem of Statistical Learning
Let $\mathcal{H}$ be a hypothesis class of functions $f:\mathcal{X}\to \lbrace 0,1 \rbrace$, where $\mathcal{X}$ is the domain. Let the loss function be the $0-1$ loss. Then the following statements are equivalent:
$\mathcal{H}$ has the uniform convergence property.
Any ERM rule is a successful agnostic PAC-learner for $\mathcal{H}$.
$\mathcal{H}$ is agnostic PAC-learnable.
$\mathcal{H}$ is PAC-learnable.
Any ERM rule is a successful PAC-learner for $\mathcal{H}$.