+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ FASTopic is a neural topic model based on Dual Semantic-relation Reconstruction.
+++Turftopic contains an implementation repurposed for our API, but the implementation is mostly from the original FASTopic package.
+
 This part of the documentation is still under construction
This part of the documentation is still under construction
Wu, X., Nguyen, T., Zhang, D. C., Wang, W. Y., & Luu, A. T. (2024). FASTopic: A Fast, Adaptive, Stable, and Transferable Topic Modeling Paradigm. ArXiv Preprint ArXiv:2405.17978.
+turftopic.models.fastopic.FASTopic
+
+
+
+ Bases: ContextualModel
Implementation of the FASTopic model with a Turftopic API. +The implementation is based on the original FASTopic package, +but is adapted for optimal use in Turftopic (you can pre-compute embeddings for instance).
+You will need to install torch to use this model.
+pip install turftopic[torch]
+## OR:
+pip install turftopic[pyro-ppl]
+from turftopic import FASTopic
+
+corpus: list[str] = ["some text", "more text", ...]
+
+model = FASTopic(10).fit(corpus)
+model.print_topics()
+Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ n_components
+ |
+
+ int
+ |
+
+
+
+ Number of topics. If you're using priors on the weight, +feel free to overshoot with this value. + |
+ + required + | +
+ encoder
+ |
+
+ Union[Encoder, str]
+ |
+
+
+
+ Model to encode documents/terms, all-MiniLM-L6-v2 is the default. + |
+
+ 'sentence-transformers/all-MiniLM-L6-v2'
+ |
+
+ vectorizer
+ |
+
+ Optional[CountVectorizer]
+ |
+
+
+
+ Vectorizer used for term extraction. +Can be used to prune or filter the vocabulary. + |
+
+ None
+ |
+
+ random_state
+ |
+
+ Optional[int]
+ |
+
+
+
+ Random state to use so that results are exactly reproducible. + |
+
+ None
+ |
+
+ DT_alpha
+ |
+
+ float
+ |
+
+
+
+ Sinkhorn alpha between document embeddings and topic embeddings. + |
+
+ 3.0
+ |
+
+ TW_alpha
+ |
+
+ float
+ |
+
+
+
+ Sinkhorn alpha between topic embeddings and word embeddings. + |
+
+ 2.0
+ |
+
+ theta_temp
+ |
+
+ float
+ |
+
+
+
+ Temperature parameter of used in softmax to compute topic probabilities in documents. + |
+
+ 1.0
+ |
+
+ n_epochs
+ |
+
+ int
+ |
+
+
+
+ Number of epochs to train the model for. + |
+
+ 200
+ |
+
+ learning_rate
+ |
+
+ float
+ |
+
+
+
+ Learning rate for the ADAM optimizer. + |
+
+ 0.002
+ |
+
+ device
+ |
+
+ str
+ |
+
+
+
+ Device to run the model on. Defaults to CPU. + |
+
+ 'cpu'
+ |
+
turftopic/models/fastopic.py15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 | |
transform(raw_documents, embeddings=None)
+
+Infers topic importances for new documents based on a fitted model.
+ + +Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ raw_documents
+ |
+ + | +
+
+
+ Documents to fit the model on. + |
+ + required + | +
+ embeddings
+ |
+
+ Optional[ndarray]
+ |
+
+
+
+ Precomputed document encodings. + |
+
+ None
+ |
+
Returns:
+| Type | +Description | +
|---|---|
+ ndarray of shape (n_dimensions, n_topics)
+ |
+
+
+
+ Document-topic matrix. + |
+
turftopic/models/fastopic.py170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 | |
GMM is a generative probabilistic model over the contextual embeddings. +The model assumes that contextual embeddings are generated from a mixture of underlying Gaussian components. +These Gaussian components are assumed to be the topics.
+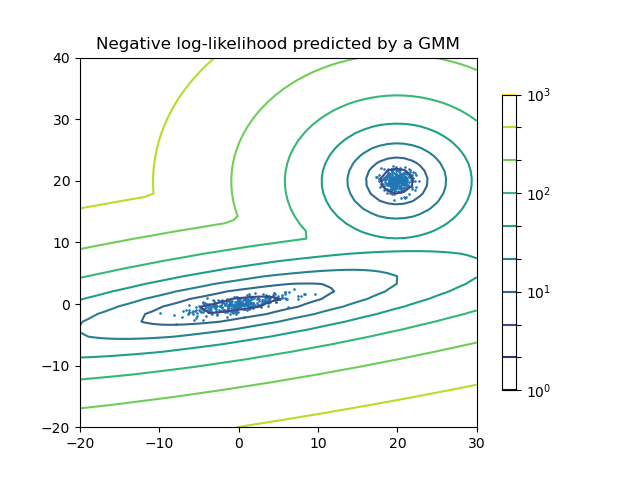 +
+ GMM assumes that the embeddings are generated according to the following stochastic process:
+Priors are optionally imposed on the model parameters. +The model is fitted either using expectation maximization or variational inference.
+After the model is fitted, soft topic labels are inferred for each document. +A document-topic-matrix (\(T\)) is built from the likelihoods of each component given the document encodings.
+Or in other words for document \(i\) and topic \(z\) the matrix entry will be: \(T_{iz} = p(\rho_i|\mu_z, \Sigma_z)\)
+Term importances for the discovered Gaussian components are estimated post-hoc using a technique called Soft c-TF-IDF, +an extension of c-TF-IDF, that can be used with continuous labels.
+Let \(X\) be the document term matrix where each element (\(X_{ij}\)) corresponds with the number of times word \(j\) occurs in a document \(i\). +Soft Class-based tf-idf scores for terms in a topic are then calculated in the following manner:
+GMM is also capable of dynamic topic modeling. This happens by fitting one underlying mixture model over the entire corpus, as we expect that there is only one semantic model generating the documents. +To gain temporal representations for topics, the corpus is divided into equal, or arbitrarily chosen time slices, and then term importances are estimated using Soft-c-TF-IDF for each of the time slices separately.
+Gaussian Mixtures can in some sense be considered a fuzzy clustering model.
+Since we assume the existence of a ground truth label for each document, the model technically cannot capture multiple topics in a document, +only uncertainty around the topic label.
+This makes GMM better at accounting for documents which are the intersection of two or more semantically close topics.
+Another important distinction is that clustering topic models are typically transductive, while GMM is inductive. +This means that in the case of GMM we are inferring some underlying semantic structure, from which the different documents are generated, +instead of just describing the corpus at hand. +In practical terms this means that GMM can, by default infer topic labels for documents, while (some) clustering models cannot.
+GMM can be a bit tedious to run at scale. This is due to the fact, that the dimensionality of parameter space increases drastically with the number of mixture components, and with embedding dimensionality. +To counteract this issue, you can use dimensionality reduction. We recommend that you use PCA, as it is a linear and interpretable method, and it can function efficiently at scale.
+++Through experimentation on the 20Newsgroups dataset I found that with 20 mixture components and embeddings from the
+all-MiniLM-L6-v2embedding model + reducing the dimensionality of the embeddings to 20 with PCA resulted in no performance decrease, but ran multiple times faster. + Needless to say this difference increases with the number of topics, embedding and corpus size.
from turftopic import GMM
+from sklearn.decomposition import PCA
+
+model = GMM(20, dimensionality_reduction=PCA(20))
+
+# for very large corpora you can also use Incremental PCA with minibatches
+
+from sklearn.decomposition import IncrementalPCA
+
+model = GMM(20, dimensionality_reduction=IncrementalPCA(20))
+turftopic.models.gmm.GMM
+
+
+
+ Bases: ContextualModel, DynamicTopicModel
Multivariate Gaussian Mixture Model over document embeddings. +Models topics as mixture components.
+from turftopic import GMM
+
+corpus: list[str] = ["some text", "more text", ...]
+
+model = GMM(10, weight_prior="dirichlet_process").fit(corpus)
+model.print_topics()
+Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ n_components
+ |
+
+ int
+ |
+
+
+
+ Number of topics. If you're using priors on the weight, +feel free to overshoot with this value. + |
+ + required + | +
+ encoder
+ |
+
+ Union[Encoder, str]
+ |
+
+
+
+ Model to encode documents/terms, all-MiniLM-L6-v2 is the default. + |
+
+ 'sentence-transformers/all-MiniLM-L6-v2'
+ |
+
+ vectorizer
+ |
+
+ Optional[CountVectorizer]
+ |
+
+
+
+ Vectorizer used for term extraction. +Can be used to prune or filter the vocabulary. + |
+
+ None
+ |
+
+ weight_prior
+ |
+
+ Literal['dirichlet', 'dirichlet_process', None]
+ |
+
+
+
+ Prior to impose on component weights, if None, +maximum likelihood is optimized with expectation maximization, +otherwise variational inference is used. + |
+
+ None
+ |
+
+ gamma
+ |
+
+ Optional[float]
+ |
+
+
+
+ Concentration parameter of the symmetric prior. +By default 1/n_components is used. +Ignored when weight_prior is None. + |
+
+ None
+ |
+
+ dimensionality_reduction
+ |
+
+ Optional[TransformerMixin]
+ |
+
+
+
+ Optional dimensionality reduction step before GMM is run. +This is recommended for very large datasets with high dimensionality, +as the number of parameters grows vast in the model otherwise. +We recommend using PCA, as it is a linear solution, and will likely +result in Gaussian components. +For even larger datasets you can use IncrementalPCA to reduce +memory load. + |
+
+ None
+ |
+
+ random_state
+ |
+
+ Optional[int]
+ |
+
+
+
+ Random state to use so that results are exactly reproducible. + |
+
+ None
+ |
+
Attributes:
+| Name | +Type | +Description | +
|---|---|---|
weights_ |
+
+ ndarray of shape (n_components)
+ |
+
+
+
+ Weights of the different mixture components. + |
+
turftopic/models/gmm.py18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 | |
transform(raw_documents, embeddings=None)
+
+Infers topic importances for new documents based on a fitted model.
+ + +Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ raw_documents
+ |
+ + | +
+
+
+ Documents to fit the model on. + |
+ + required + | +
+ embeddings
+ |
+
+ Optional[ndarray]
+ |
+
+
+
+ Precomputed document encodings. + |
+
+ None
+ |
+
Returns:
+| Type | +Description | +
|---|---|
+ ndarray of shape (n_dimensions, n_topics)
+ |
+
+
+
+ Document-topic matrix. + |
+
turftopic/models/gmm.py143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 | |
KeyNMF is a topic model that relies on contextually sensitive embeddings for keyword retrieval and term importance estimation, +while taking inspiration from classical matrix-decomposition approaches for extracting topics.
+ +
+ Here's an example of how you can fit and interpret a KeyNMF model in the easiest way.
+from turftopic import KeyNMF
+
+model = KeyNMF(10, top_n=6)
+model.fit(corpus)
+
+model.print_topics()
+The first step of the process is gaining enhanced representations of documents by using contextual embeddings. +Both the documents and the vocabulary get encoded with the same sentence encoder. +Keywords are assigned to each document based on the cosine similarity of the document embedding to the embedded words in the document. +Only the top K words with positive cosine similarity to the document are kept. +These keywords are then arranged into a document-term importance matrix where each column represents a keyword that was encountered in at least one document, +and each row is a document. The entries in the matrix are the cosine similarities of the given keyword to the document in semantic space.
+For each document \(d\):
+For each word \(w\) in the document \(d\):
+Let \(K_d\) be the set of \(N\) keywords with the highest cosine similarity to document \(d\).
+Arrange positive keyword similarities into a keyword matrix \(M\) where the rows represent documents, and columns represent unique keywords.
+You can do this step manually if you want to precompute the keyword matrix. +Keywords are represented as dictionaries mapping words to keyword importances.
+model.extract_keywords(["Cars are perhaps the most important invention of the last couple of centuries. They have revolutionized transportation in many ways."])
+[{'transportation': 0.44713873,
+ 'invention': 0.560524,
+ 'cars': 0.5046208,
+ 'revolutionized': 0.3339205,
+ 'important': 0.21803442}]
+A precomputed Keyword matrix can also be used to fit a model:
+keyword_matrix = model.extract_keywords(corpus)
+model.fit(None, keywords=keyword_matrix)
+Topics in this matrix are then discovered using Non-negative Matrix Factorization. +Essentially the model tries to discover underlying dimensions/factors along which most of the variance in term importance +can be explained.
+Decompose \(M\) with non-negative matrix factorization: \(M \approx WH\), where \(W\) is the document-topic matrix, and \(H\) is the topic-term matrix. Non-negative Matrix Factorization is done with the coordinate-descent algorithm, minimizing square loss:
+You can fit KeyNMF on the raw corpus, with precomputed embeddings or with precomputed keywords. +
# Fitting just on the corpus
+model.fit(corpus)
+
+# Fitting with precomputed embeddings
+from sentence_transformers import SentenceTransformer
+
+trf = SentenceTransformer("all-MiniLM-L6-v2")
+embeddings = trf.encode(corpus)
+
+model = KeyNMF(10, encoder=trf)
+model.fit(corpus, embeddings=embeddings)
+
+# Fitting with precomputed keyword matrix
+keyword_matrix = model.extract_keywords(corpus)
+model.fit(None, keywords=keyword_matrix)
+Some embedding models can be used together with prompting, or encode queries and passages differently. +This is important for KeyNMF, as it is explicitly based on keyword retrieval, and its performance can be substantially enhanced by using asymmetric or prompted embeddings. +Microsoft's E5 models are, for instance, all prompted by default, and it would be detrimental to performance not to do so yourself.
+In these cases, you're better off NOT passing a string to Turftopic models, but explicitly loading the model using sentence-transformers.
Here's an example of using instruct models for keyword retrieval with KeyNMF. +In this case, documents will serve as the queries and words as the passages:
+from turftopic import KeyNMF
+from sentence_transformers import SentenceTransformer
+
+encoder = SentenceTransformer(
+ "intfloat/multilingual-e5-large-instruct",
+ prompts={
+ "query": "Instruct: Retrieve relevant keywords from the given document. Query: "
+ "passage": "Passage: "
+ },
+ # Make sure to set default prompt to query!
+ default_prompt_name="query",
+)
+model = KeyNMF(10, encoder=encoder)
+And a regular, asymmetric example:
+encoder = SentenceTransformer(
+ "intfloat/e5-large-v2",
+ prompts={
+ "query": "query: "
+ "passage": "passage: "
+ },
+ # Make sure to set default prompt to query!
+ default_prompt_name="query",
+)
+model = KeyNMF(10, encoder=encoder)
+Setting the default prompt to query is especially important, when you are precomputing embeddings, as query should always be your default prompt to embed documents with.
KeyNMF is also capable of modeling topics over time. +This happens by fitting a KeyNMF model first on the entire corpus, then +fitting individual topic-term matrices using coordinate descent based on the document-topic and document-term matrices in the given time slices.
+For each time slice \(t\):
+Here's an example of using KeyNMF in a dynamic modeling setting:
+from datetime import datetime
+
+from turftopic import KeyNMF
+
+corpus: list[str] = []
+timestamps: list[datetime] = []
+
+model = KeyNMF(5, top_n=5, random_state=42)
+document_topic_matrix = model.fit_transform_dynamic(
+ corpus, timestamps=timestamps, bins=10
+)
+You can use the print_topics_over_time() method for producing a table of the topics over the generated time slices.
++This example uses CNN news data.
+
model.print_topics_over_time()
+| Time Slice | +0_olympics_tokyo_athletes_beijing | +1_covid_vaccine_pandemic_coronavirus | +2_olympic_athletes_ioc_athlete | +3_djokovic_novak_tennis_federer | +4_ronaldo_cristiano_messi_manchester | +
|---|---|---|---|---|---|
| 2012 12 06 - 2013 11 10 | +genocide, yugoslavia, karadzic, facts, cnn | +cnn, russia, chechnya, prince, merkel | +france, cnn, francois, hollande, bike | +tennis, tournament, wimbledon, grass, courts | +beckham, soccer, retired, david, learn | +
| 2013 11 10 - 2014 10 14 | +keith, stones, richards, musician, author | +georgia, russia, conflict, 2008, cnn | +civil, rights, hear, why, should | +cnn, kidneys, traffickers, organ, nepal | +ronaldo, cristiano, goalscorer, soccer, player | +
| 2014 10 14 - 2015 09 18 | +ethiopia, brew, coffee, birthplace, anderson | +climate, sutter, countries, snapchat, injustice | +women, guatemala, murder, country, worst | +cnn, climate, oklahoma, women, topics | +sweden, parental, dads, advantage, leave | +
| 2015 09 18 - 2016 08 22 | +snow, ice, winter, storm, pets | +climate, crisis, drought, outbreaks, syrian | +women, vulnerabilities, frontlines, countries, marcelas | +cnn, warming, climate, sutter, theresa | +sutter, band, paris, fans, crowd | +
| 2016 08 22 - 2017 07 26 | +derby, epsom, sporting, race, spectacle | +overdoses, heroin, deaths, macron, emmanuel | +fear, died, indigenous, people, arthur | +siblings, amnesia, palombo, racial, mh370 | +bobbi, measles, raped, camp, rape | +
| 2017 07 26 - 2018 06 30 | +her, percussionist, drums, she, deported | +novichok, hurricane, hospital, deaths, breathing | +women, day, celebrate, taliban, international | +abuse, harassment, cnn, women, pilgrimage | +maradona, argentina, history, jadon, rape | +
| 2018 06 30 - 2019 06 03 | +athletes, teammates, celtics, white, racism | +pope, archbishop, francis, vigano, resignation | +racism, athletes, teammates, celtics, white | +golf, iceland, volcanoes, atlantic, ocean | +rape, sudanese, racist, women, soldiers | +
| 2019 06 03 - 2020 05 07 | +esports, climate, ice, racers, culver | +esports, coronavirus, pandemic, football, teams | +racers, women, compete, zone, bery | +serena, stadium, sasha, final, naomi | +kobe, bryant, greatest, basketball, influence | +
| 2020 05 07 - 2021 04 10 | +olympics, beijing, xinjiang, ioc, boycott | +covid, vaccine, coronavirus, pandemic, vaccination | +olympic, japan, medalist, canceled, tokyo | +djokovic, novak, tennis, federer, masterclass | +ronaldo, cristiano, messi, juventus, barcelona | +
| 2021 04 10 - 2022 03 16 | +olympics, tokyo, athletes, beijing, medal | +covid, pandemic, vaccine, vaccinated, coronavirus | +olympic, athletes, ioc, medal, athlete | +djokovic, novak, tennis, wimbledon, federer | +ronaldo, cristiano, messi, manchester, scored | +
You can also display the topics over time on an interactive HTML figure. +The most important words for topics get revealed by hovering over them.
+++You will need to install Plotly for this to work.
+
pip install plotly
+model.plot_topics_over_time(top_k=5)
+ +
+ KeyNMF can also be fitted in an online manner. +This is done by fitting NMF with batches of data instead of the whole dataset at once.
+We will use the batching function from the itertools recipes to produce batches.
+++In newer versions of Python (>=3.12) you can just
+from itertools import batched
def batched(iterable, n: int):
+ "Batch data into lists of length n. The last batch may be shorter."
+ if n < 1:
+ raise ValueError("n must be at least one")
+ it = iter(iterable)
+ while batch := tuple(itertools.islice(it, n)):
+ yield batch
+You can fit a KeyNMF model to a very large corpus in batches like so:
+from turftopic import KeyNMF
+
+model = KeyNMF(10, top_n=5)
+
+corpus = ["some string", "etc", ...]
+for batch in batched(corpus, 200):
+ batch = list(batch)
+ model.partial_fit(batch)
+If you desire the best results, it might make sense for you to go over the corpus in multiple epochs:
+for epoch in range(5):
+ for batch in batched(corpus, 200):
+ model.partial_fit(batch)
+This is mildly inefficient, however, as the texts need to be encoded on every epoch, and keywords need to be extracted.
+In such scenarios you might want to precompute and maybe even save the extracted keywords to disk using the extract_keywords() method.
Keywords are represented as dictionaries mapping words to keyword importances.
+model.extract_keywords(["Cars are perhaps the most important invention of the last couple of centuries. They have revolutionized transportation in many ways."])
+[{'transportation': 0.44713873,
+ 'invention': 0.560524,
+ 'cars': 0.5046208,
+ 'revolutionized': 0.3339205,
+ 'important': 0.21803442}]
+You can extract keywords in batches and save them to disk to a file format of your choice. +In this example I will use NDJSON because of its simplicity.
+import json
+from pathlib import Path
+from typing import Iterable
+
+# Here we are saving keywords to a JSONL/NDJSON file
+with Path("keywords.jsonl").open("w") as keyword_file:
+ # Doing this in batches is much more efficient than individual texts because
+ # of the encoding.
+ for batch in batched(corpus, 200):
+ batch_keywords = model.extract_keywords(batch)
+ # We serialize each
+ for keywords in batch_keywords:
+ keyword_file.write(json.dumps(keywords) + "\n")
+
+def stream_keywords() -> Iterable[dict[str, float]]:
+ """This function streams keywords from the file."""
+ with Path("keywords.jsonl").open() as keyword_file:
+ for line in keyword_file:
+ yield json.loads(line.strip())
+
+for epoch in range(5):
+ keyword_stream = stream_keywords()
+ for keyword_batch in batched(keyword_stream, 200):
+ model.partial_fit(keywords=keyword_batch)
+KeyNMF can be online fitted in a dynamic manner as well. +This is useful when you have large corpora of text over time, or when you want to fit the model on future information flowing in +and want to analyze the topics' changes over time.
+When using dynamic online topic modeling you have to predefine the time bins that you will use, as the model can't infer these from the data.
+from datetime import datetime
+
+# We will bin by years in a period of 2020-2030
+bins = [datetime(year=y, month=1, day=1) for y in range(2020, 2030 + 2, 1)]
+You can then online fit a dynamic topic model with partial_fit_dynamic().
model = KeyNMF(5, top_n=10)
+
+corpus: list[str] = [...]
+timestamps: list[datetime] = [...]
+
+for batch in batched(zip(corpus, timestamps)):
+ text_batch, ts_batch = zip(*batch)
+ model.partial_fit_dynamic(text_batch, timestamps=ts_batch, bins=bins)
+When you suspect that subtopics might be present in the topics you find with the model, KeyNMF can be used to discover topics further down the hierarchy.
+This is done by utilising a special case of weighted NMF, where documents are weighted by how high they score on the parent topic. +In other words:
+To create a hierarchical model, you can use the hierarchy property of the model.
# This divides each of the topics in the model to 3 subtopics.
+model.hierarchy.divide_children(n_subtopics=3)
+print(model.hierarchy)
+For a detailed tutorial on hierarchical modeling click here.
+turftopic.models.keynmf.KeyNMF
+
+
+
+ Bases: ContextualModel, DynamicTopicModel
Extracts keywords from documents based on semantic similarity of +term encodings to document encodings. +Topics are then extracted with non-negative matrix factorization from +keywords' proximity to documents.
+from turftopic import KeyNMF
+
+corpus: list[str] = ["some text", "more text", ...]
+
+model = KeyNMF(10, top_n=10).fit(corpus)
+model.print_topics()
+Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ n_components
+ |
+
+ int
+ |
+
+
+
+ Number of topics. + |
+ + required + | +
+ encoder
+ |
+
+ Union[Encoder, str]
+ |
+
+
+
+ Model to encode documents/terms, all-MiniLM-L6-v2 is the default. + |
+
+ 'sentence-transformers/all-MiniLM-L6-v2'
+ |
+
+ vectorizer
+ |
+
+ Optional[CountVectorizer]
+ |
+
+
+
+ Vectorizer used for term extraction. +Can be used to prune or filter the vocabulary. + |
+
+ None
+ |
+
+ top_n
+ |
+
+ int
+ |
+
+
+
+ Number of keywords to extract for each document. + |
+
+ 25
+ |
+
+ random_state
+ |
+
+ Optional[int]
+ |
+
+
+
+ Random state to use so that results are exactly reproducible. + |
+
+ None
+ |
+
turftopic/models/keynmf.py22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 +213 +214 +215 +216 +217 +218 +219 +220 +221 +222 +223 +224 +225 +226 +227 +228 +229 +230 +231 +232 +233 +234 +235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 +248 +249 +250 +251 +252 +253 +254 +255 +256 +257 +258 +259 +260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 +285 +286 +287 +288 +289 +290 +291 +292 +293 +294 +295 +296 +297 +298 +299 +300 +301 +302 +303 +304 +305 +306 +307 +308 +309 +310 +311 +312 +313 +314 +315 +316 +317 +318 +319 +320 +321 +322 +323 +324 +325 +326 +327 +328 +329 +330 +331 +332 +333 +334 +335 +336 +337 +338 +339 +340 +341 +342 +343 +344 +345 +346 +347 +348 +349 +350 +351 +352 +353 +354 +355 +356 +357 +358 +359 +360 +361 +362 +363 +364 +365 +366 +367 +368 +369 +370 +371 +372 +373 +374 +375 +376 +377 +378 +379 +380 +381 +382 +383 +384 +385 +386 +387 +388 +389 +390 +391 +392 +393 +394 +395 +396 +397 +398 +399 +400 +401 +402 +403 +404 +405 +406 +407 +408 +409 +410 +411 +412 +413 +414 +415 +416 +417 +418 +419 +420 +421 +422 +423 +424 +425 +426 +427 +428 +429 +430 +431 +432 +433 +434 | |
extract_keywords(batch_or_document, embeddings=None)
+
+Extracts keywords from a document or a batch of documents.
+ + +Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ batch_or_document
+ |
+
+ Union[str, list[str]]
+ |
+
+
+
+ A single document or a batch of documents. + |
+ + required + | +
+ embeddings
+ |
+
+ Optional[ndarray]
+ |
+
+
+
+ Precomputed document embeddings. + |
+
+ None
+ |
+
turftopic/models/keynmf.py82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 | |
fit(raw_documents=None, y=None, embeddings=None, keywords=None)
+
+Fits topic model and returns topic importances for documents.
+ + +Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ raw_documents
+ |
+ + | +
+
+
+ Documents to fit the model on. + |
+
+ None
+ |
+
+ embeddings
+ |
+
+ Optional[ndarray]
+ |
+
+
+
+ Precomputed document encodings. + |
+
+ None
+ |
+
+ keywords
+ |
+
+ Optional[list[dict[str, float]]]
+ |
+
+
+
+ Precomputed keyword dictionaries. + |
+
+ None
+ |
+
turftopic/models/keynmf.py193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 | |
fit_transform(raw_documents=None, y=None, embeddings=None, keywords=None)
+
+Fits topic model and returns topic importances for documents.
+ + +Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ raw_documents
+ |
+ + | +
+
+
+ Documents to fit the model on. + |
+
+ None
+ |
+
+ embeddings
+ |
+
+ Optional[ndarray]
+ |
+
+
+
+ Precomputed document encodings. + |
+
+ None
+ |
+
+ keywords
+ |
+
+ Optional[list[dict[str, float]]]
+ |
+
+
+
+ Precomputed keyword dictionaries. + |
+
+ None
+ |
+
Returns:
+| Type | +Description | +
|---|---|
+ ndarray of shape (n_dimensions, n_topics)
+ |
+
+
+
+ Document-topic matrix. + |
+
turftopic/models/keynmf.py148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 | |
partial_fit(raw_documents=None, embeddings=None, keywords=None)
+
+Online fits KeyNMF on a batch of documents.
+ + +Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ raw_documents
+ |
+
+ Optional[list[str]]
+ |
+
+
+
+ Documents to fit the model on. + |
+
+ None
+ |
+
+ embeddings
+ |
+
+ Optional[ndarray]
+ |
+
+
+
+ Precomputed document encodings. + |
+
+ None
+ |
+
+ keywords
+ |
+
+ Optional[list[dict[str, float]]]
+ |
+
+
+
+ Precomputed keyword dictionaries. + |
+
+ None
+ |
+
turftopic/models/keynmf.py249 +250 +251 +252 +253 +254 +255 +256 +257 +258 +259 +260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 +285 +286 +287 +288 +289 +290 | |
partial_fit_dynamic(raw_documents=None, timestamps=None, embeddings=None, keywords=None, bins=10)
+
+Online fits Dynamic KeyNMF on a batch of documents.
+ + +Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ raw_documents
+ |
+ + | +
+
+
+ Documents to fit the model on. + |
+
+ None
+ |
+
+ embeddings
+ |
+
+ Optional[ndarray]
+ |
+
+
+
+ Precomputed document encodings. + |
+
+ None
+ |
+
+ keywords
+ |
+
+ Optional[list[dict[str, float]]]
+ |
+
+
+
+ Precomputed keyword dictionaries. + |
+
+ None
+ |
+
+ timestamps
+ |
+
+ Optional[list[datetime]]
+ |
+
+
+
+ List of timestamps for the batch. + |
+
+ None
+ |
+
+ bins
+ |
+
+ Union[int, list[datetime]]
+ |
+
+
+
+ Explicit time bin edges for the dynamic model. + |
+
+ 10
+ |
+
turftopic/models/keynmf.py378 +379 +380 +381 +382 +383 +384 +385 +386 +387 +388 +389 +390 +391 +392 +393 +394 +395 +396 +397 +398 +399 +400 +401 +402 +403 +404 +405 +406 +407 +408 +409 +410 +411 +412 +413 +414 +415 +416 +417 +418 +419 +420 +421 +422 +423 +424 +425 +426 +427 +428 +429 +430 +431 +432 +433 +434 | |
transform(raw_documents=None, embeddings=None, keywords=None)
+
+Infers topic importances for new documents based on a fitted model.
+ + +Parameters:
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
+ raw_documents
+ |
+ + | +
+
+
+ Documents to fit the model on. + |
+
+ None
+ |
+
+ embeddings
+ |
+
+ Optional[ndarray]
+ |
+
+
+
+ Precomputed document encodings. + |
+
+ None
+ |
+
+ keywords
+ |
+
+ Optional[list[dict[str, float]]]
+ |
+
+
+
+ Precomputed keyword dictionaries. + |
+
+ None
+ |
+
Returns:
+| Type | +Description | +
|---|---|
+ ndarray of shape (n_dimensions, n_topics)
+ |
+
+
+
+ Document-topic matrix. + |
+
turftopic/models/keynmf.py217 +218 +219 +220 +221 +222 +223 +224 +225 +226 +227 +228 +229 +230 +231 +232 +233 +234 +235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 | |
vectorize(raw_documents=None, embeddings=None, keywords=None)
+
+Creates document-term-matrix from documents.
+ +turftopic/models/keynmf.py102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 | |