OCR(Optical Character Recognition)即光学字符识别的缩写,可应用于文档资料、证件票据等场景,针对复杂图文场景通常把任务分解为(文本检测+文本识别)两个子任务。中文是承载中国文化的重要工具,携带着丰富且精确的信息,在日常生活中经常能见到带有中文的图像或视频,挖掘其中的信息能提升人民数字化生活的便捷性。
- 中文文本检测(Detection)是找出图像或视频中文字的位置

- 中文文本识别(Recognition)是将图像信息转换为文字信息

难点在于:
-
自然场景中文本具有多样性:文本检测受到文字颜色、大小、字体、形状、方向、语言、以及文本长度的影响;
-
复杂的背景和干扰;文本检测受到图像失真,模糊,低分辨率,阴影,亮度等因素的影响;
-
文本密集甚至重叠会影响文字的检测;
-
文字存在局部一致性,文本行的一小部分,也可视为是独立的文本;
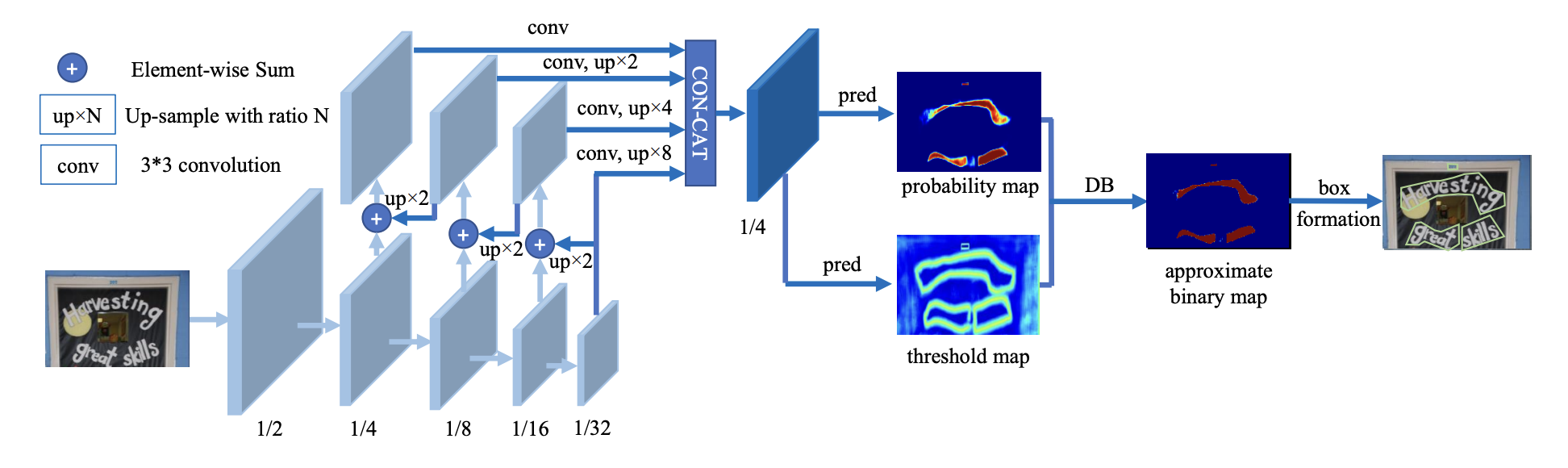
DBNet针对基于分割的方法需要使用阈值进行二值化处理而导致后处理耗时的问题,提出了可学习阈值并巧妙地设计了一个近似于阶跃函数的二值化函数,使得分割网络在训练的时候能端对端的学习文本分割的阈值。自动调节阈值不仅带来精度的提升,同时简化了后处理,提高了文本检测的性能。
Jupyter Notebook编译环境,详情查看Detection
1.可查看日志文件Detection/train.log
[2021/12/26 09:56:42] root INFO: best metric, hmean: 0.6280081697895391, precision: 0.6685573832482511, recall: 0.5920964501004689, fps: 24.08220105239744, best_epoch: 167
2.默认配置文件'det_mv3_db.yml'训练的400个epoch,训练过程中使用visualdl,验证集中EVAL/hmean最高指标为0.62758.


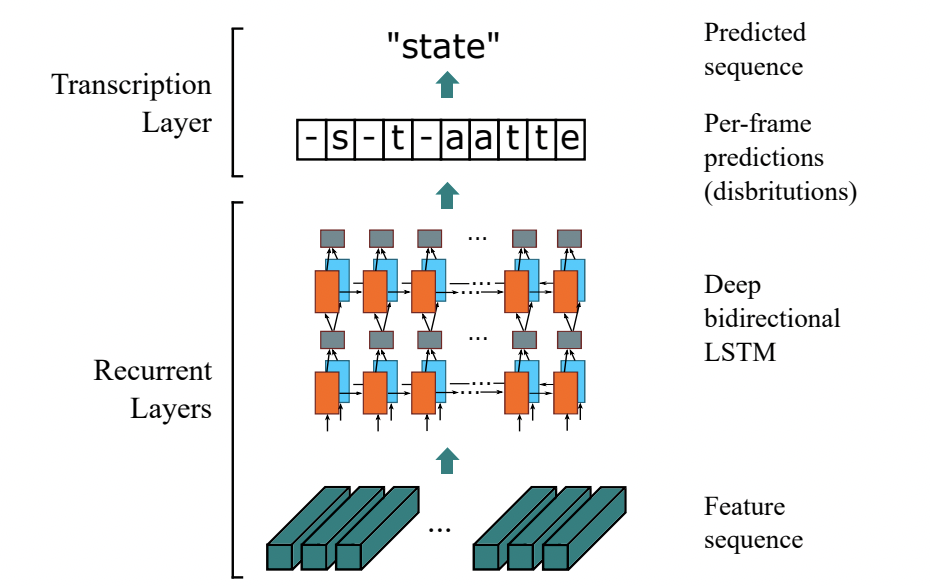
CRNN (Convolutional Recurrent Neural Network)文本识别算法引入了双向 LSTM(Long Short-Term Memory) 用来增强上下文建模,通过实验证明双向LSTM模块可以有效的提取出图片中的上下文信息。最终将输出的特征序列输入到CTC模块,直接解码序列结果。该结构被验证有效,并广泛应用在文本识别任务中。
Jupyter Notebook编译环境,详情查看Recognition
1.可查看日文件Recognition/train.log
[2021/12/27 19:15:35] root INFO: best metric, acc: 0.6419997860000712, norm_edit_dis: 0.8262728930006751, fps: 4110.497800673927, best_epoch: 93
2.加载预训练模型ch_ppocr_server_v2.0_rec_pre/best_accuracy,训练过程启动visualdl如图所示

本项目使用PaddleOCR对中文文本数据集进行检测任务和识别任务,采用预训练加微调的方式进行模型训练,开始阶段评价指标hmean从0开始缓慢上升,训练次数达到50次后开始评估,精度曲线开始接近收敛,若要进一步提升可尝试如下配置方式。
- 检测任务优化配置
Architecture: # 模型结构定义
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3 # 配置骨干网络
scale: 0.5
model_name: large
disable_se: True # 去除SE模块
Neck:
name: DBFPN # 配置DBFPN
out_channels: 96 # 配置 inner_channels
Head:
name: DBHead
k: 50
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine # 配置cosine学习率下降策略
learning_rate: 0.001 # 初始学习率
warmup_epoch: 2 # 配置学习率预热策略
regularizer:
name: 'L2' # 配置L2正则
factor: 0 # 正则项的权重
- 识别任务优化配置
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine # 配置Cosine 学习率下降策略
learning_rate: 0.001
warmup_epoch: 5 # 配置预热学习率
regularizer:
name: 'L2' # 配置L2正则
factor: 0.00001
Architecture:
model_type: rec
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV3 # 配置Backbone
scale: 0.5
model_name: small
small_stride: [1, 2, 2, 2] # 配置下采样的stride
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 48 # 配置最后一层全连接层的维度
Head:
name: CTCHead
fc_decay: 0.00001
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/
label_file_list: ["./train_data/train_list.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- RecAug: # 配置数据增强BDA和TIA,TIA默认使用
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 320]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 256
drop_last: True
num_workers: 8
Real-time Scene Text Detection with Differentiable Binarization