- Hadoop Theory link
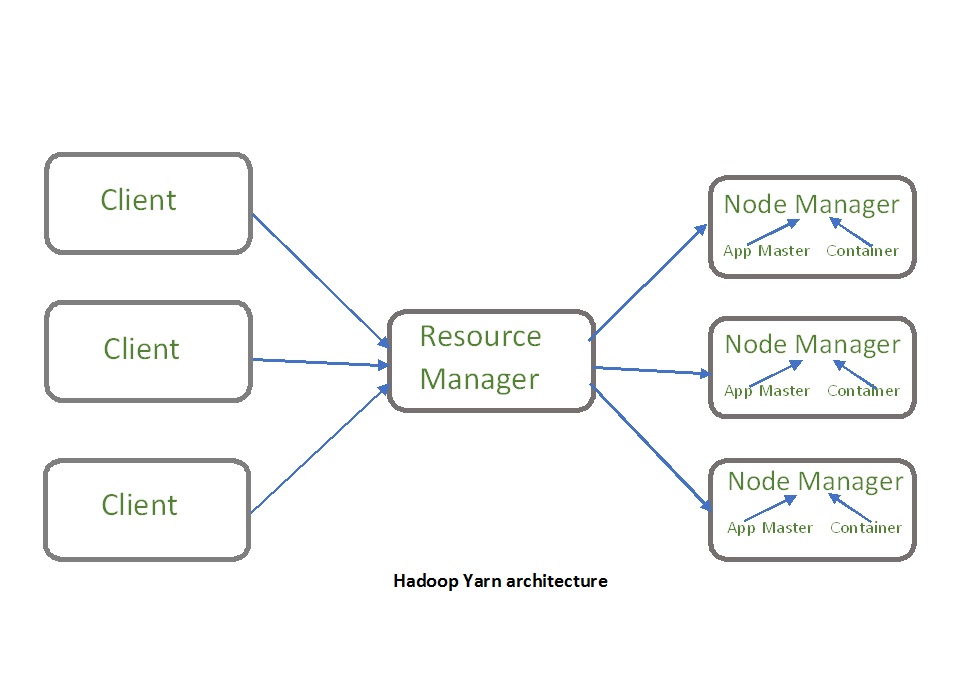
- Yarn link
- Hadoop marreduce local disk answer search local in find local
- Apache Spark spark
- DAG & RDD Architecture
- Spark Streaming link
- Spark Tutorial With Scala link
- Pig Installation link
- Flume Installation link
- Hive internal vs external link
- Bucketing link
- If mapreduce take 3tb of data it give 3tb data only not 3x3TB
- DDL,DML,DCL link
- Squoop link
- Mini_Project link
- Pyspark link
- Hbase link
- Case Study link
- Hadoop rough C link
- Python classes link
- Kafka link
- Spark link
- Scala link
DataBase = DB Engine + Data Storage
- MySql default size is 256TB or 2^8
- MySql at peak 65,536TB or 2^16
- Mapreduce doesn't deals with local HDFS
- Hadoop is a framework
- JPS stands for java process status
- To change block size go to hdfs-site.xml
- Replication factor can be change in core-site.xml
- 512 mb means 4 block and if 514 mb is consumed so it will take only 2mb extra not the 128mb complete advantage
- Rack failure is not very common while block failure is
- Rack with minumun latency will select as original while 2nd most latenct and 3rd most is rep2 and rep3
- hadoop fs -ls / # fs stands of file system while / absolute path
- hdfs dfs -ls / # dfs stands for distributed file system
- hadoop use local storage in intermediate processes because hdfs create replicatin while local storage doesn't
- load data inpath command is use to load data into hive table. 'LOCAL' signifies that the input file is on the local file system. If 'LOCAL' is omitted then it looks for the file in HDFS. load data inpath '/directory-path/file. csv' into mytable; and load data local inpath '/local-directory-path/file into mytable;
- ETL stands for Extract, Transform and Load. The ETL process typically extracts data from the source / transactional systems, transforms it to fit the model of data warehouse and finally loads it to the data warehouse.
Data classified in three types
- Structured-: RDBMS(dates, phone no)
- Semi-structured-: XMl, Json ,HTML
- Unstructured-: Word, PDF, Text
In Mrv1 there is some problem related to job tracker so we go form mrv2 with yarn
Types of Nodes
- Name Node(Master HDFS)-: Stores meta data like name, address required less computation power also handle replication factor
- Data Node(Slave HDFS)-: Store the physical data required more computation
- Secondary Name Node-: Use for checkpoint operation
- Resource Manager(Master Yarn MRV2)-: Manage the resources allocate from container where physical drives are present and handles the cliend request(map reduce)
- Node Manager(Slave Yarn MRV2)-: Perform the operation allocated by resource manager
- Job Tracker(Master Mapreduce)-: the service within Hadoop that is responsible for taking client requests
- Task Tracker(Slave Mapreduce)-: A TaskTracker is a node in the cluster that accepts tasks - Map, Reduce and Shuffle operations - from a JobTracker.
- Hadoop is not good to handle small files so we go for sequential file that is the collection of block files
- to run java program in python use AVRO

-m 1 for primary key if it consist of primary key no need to use primary key provide distributed architecture m means mapper 1 2 3 is number of mapper
sqoop-import --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com/cdb21dw011 --username cdb22dw011 -P --table StudentData --target-dir /StudentData1 -m 1
sqoop-import --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com/cdb21dw011 --username cdb22dw011 -P --table StudentData --where "gender='Female'" --target-dir /StudentDataFemale -m 1
sqoop-import --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com/cdb21dw011 --username cdb22dw011 -P --table demo --target-dir /demo123
hadoop fs -cat /demo1/part*
or
hadoop fs -cat /demo1/part-m-0000
or
hadoop fs -cat /demo1/part-m-0001
sqoop-export --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com/cdb21dw011 --username cdb22dw011 -P --table priyanshu --export-dir /StudentData1/part*
sqoop-import --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com \ --username cdb22dw011 root –P \ --table StudentData1 \ --hive-import -m 1
sqoop-import --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com/cdb21dw011 --username cdb22dw011 -P --table
sqoop-import --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com/test --username cdb22dw011 -P --table customer --incremental append --check-column cust_id --last-value 115 --target-dir /customer
- Tabular form
- developed by facebook
- no indexing
- Use for datawarehousing
- All failure goes to mapreduce
- Hive is a powerful tool for ETL, data warehousing for Hadoop, and a database for Hadoop. It is, however, relatively slow compared with traditional databases. It doesn't offer all the same SQL features or even the same database features as traditional databases.

Two types of tables
- Managed table-: use when only hive having full control over data like if droped table it will remove all data by dedfaul table is managed or internal
- External table-: In this it doesn't have full control over the data use External to define external
cp /home/ubh01/apache-hive-2.3.2-bin/lib/hive-common-2.3.2.jar /home/ubh01/sqoop-1.4.7.bin__hadoop-2.6.0/lib/
hdfs dfs -rm -r /user/ubh01/customer
sqoop-import --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com/test --username cdb22dw011 -P --table customer --hive-import
hdfs dfs -ls /customer
hdfs dfs -get /customer/part* /home/ubh01
cat part* > customer.txt
hdfs dfs -mkdir /input
hdfs dfs -put /home/ubh01/customer.txt /input
sqoop-export --connect jdbc:mysql://cdb22dw011.c0lf9xyp8cv9.ap-south-1.rds.amazonaws.com/test --username cdb22dw011 -P --table customer --update-key cust_id --update-mode allowinsert --export-dir /input/customer.txt
hive> ALTER TABLE tablename
SET TBLPROPERTIES ("skip.header.line.count"="1");
// if given managed table than it is internal table
hive> describe extended test;
hive> create table priyanshu(age int, gender string,name string,roll int, email string) row format delimited fields terminated by ',' TBLPROPERTIES ("skip.header.line.count"="1");
hive> create external table priyanshu(age int, gender string,name string,roll int, email string) row format delimited fields terminated by ',' TBLPROPERTIES ("skip.header.line.count"="1");
hive> load data inpath '/StudentData1' overwrite into table priyanshu;
hive> describe tablename;
hive> select count (*) from tablename;
hive> create table priyanshu(
age int,
gender string,
name string,
course string,
roll int,
marks int,
email string)
row format delimited
fields terminated by ','
TBLPROPERTIES ("skip.header.line.count"="1");
=============================================================================
# Load the data from HDFS Location -> move the file from original location to hive architecture local
#if you drop the data original file is lost
hive> load data inpath '/karthick/StudentData.csv' overwrite into table karthick;
=============================================================================
#Load from the Local File System
#Keep the original file from local file system
hive> load data local inpath '/home/ubh01/Desktop/StudentData.csv' overwrite into table karthick;
============================
- Partion make query response time faster
- Dynamic partion consume more time comparerd to static partion

insert into table dummy select * from karthick;
hive> create table stat_part(
> age int,
> gender string,
> name string,
> roll int,
> marks string,
> email string
> )partitioned by (course string);
hive> insert into table stat_part partition(course = 'DB') select age,gender,name,roll, marks,email from karthick where course = 'DB';
create table dyna_part(
age int,
gender string,
name string,
roll int,
marks string,
email string
)partitioned by (course string);
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table dyna_part partition(course) select age,gender,name,roll, marks,email,course from karthick where course = 'DB';
# dynmaic partion does not required column name
hadoop fs -cat /user/hive/warehouse/name_table/000000_0
hadoop fs -cat /user/hive/warehouse/name_table/000001_0
so on
Partioning work on only if it has unique data or column while here in bucketing we working with non unique value through hashing
select distinct(age) from priyanshu;
create table priyanshu_buck(
age int,
gender string,
name string,
course string,
roll int,
marks int,
email string)
clustered by(age) into 2 buckets stored as textfile;
// 2 buckets means mod by 2 example in above student database we have 2 age 28,29 28%2=0 while 29%2=1 so according to this it will divide
insert into priyanshu_buck select * from priyanshu;
create table priyanshu_buck1(
age int,
gender string,
name string,
course string,
roll int,
marks int,
email string)
clustered by(course) into 6 buckets stored as textfile;
Apache Hbase refer
NoSQL is used for Big data and real-time web apps. For example, companies like Twitter, Facebook and Google collect terabytes of user data every single day. NoSQL database stands for “Not Only SQL” or “Not SQL.” Though a better term would be “NoREL”, NoSQL caught on. Carl Strozz introduced the NoSQL concept in 1998
- NOSQL follow CAP properties consistency, Availability and Partitioning
- Consistency-: Same data visible to all in any circumstances
- Availability-: Even if node failure data is available
- Partioning-: Maintain the work even in case of n/w failure
Here we use nosql database which is non-tabular database because now a days data originate in multiple format
HBase is a column-oriented non-relational database management system that runs on top of Hadoop Distributed File System (HDFS). HBase provides a fault-tolerant way of storing sparse data sets, which are common in many big data use cases.
- HBase required 2 things only CP consistency and partioning third one handle by HDFS
>> cd $HBASE_HOME/bin/
>> start-hbase.sh
>> hbase shell
hbase(main):008:0> table_help
Help for table-reference commands.
You can either create a table via 'create' and then manipulate the table via commands like 'put', 'get', etc.
See the standard help information for how to use each of these commands.
However, as of 0.96, you can also get a reference to a table, on which you can invoke commands.
For instance, you can get create a table and keep around a reference to it via:
hbase> t = create 't', 'cf'
Or, if you have already created the table, you can get a reference to it:
hbase> t = get_table 't'
You can do things like call 'put' on the table:
hbase> t.put 'r', 'cf:q', 'v'
which puts a row 'r' with column family 'cf', qualifier 'q' and value 'v' into table t.
To read the data out, you can scan the table:
hbase> t.scan
which will read all the rows in table 't'.
Essentially, any command that takes a table name can also be done via table reference.
Other commands include things like: get, delete, deleteall,
get_all_columns, get_counter, count, incr. These functions, along with
the standard JRuby object methods are also available via tab completion.
For more information on how to use each of these commands, you can also just type:
hbase> t.help 'scan'
which will output more information on how to use that command.
You can also do general admin actions directly on a table; things like enable, disable,
flush and drop just by typing:
hbase> t.enable
hbase> t.flush
hbase> t.disable
hbase> t.drop
Note that after dropping a table, your reference to it becomes useless and further usage
is undefined (and not recommended).
>> status
>> version
>> whoami
>> table_help
>> list
>> create 'sc-tb1' , 'tb1-cf1'
>> get_table 'sc-tb1'
- Hbase follow column oriented architecture
- It follow consistency and partion while droping the availabilty which is being handle by hdfs
- focused on unstructured data
Apache Kafka referal
>> cd $KAFKA_HOME
>> follow the referal
kafka-topics.sh
kafka-topics.sh --bootstrap-server localhost:9092 --list
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create --partitions 3
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create --partitions 3 --replication-factor 2
# Create a topic (working)
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create --partitions 3 --replication-factor 1
# List topics
kafka-topics.sh --bootstrap-server localhost:9092 --list
# Describe a topic
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --describe
# Delete a topic
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --delete
# (only works if delete.topic.enable=true)
# consuming
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first_topic
# other terminal
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first_topic
- handle 100mb r/w data per second
- immutable
- compress msg in batches
- Developed by linkedin
- focused on consumer and producer as dull
- 160000 msg per sec
- real time msg feed
- zookeper is use to check wheather the node is alive or not
- without zookeper it's a kraft mode
Spark Socket Streaming
>> nano cdb.py
import pyspark
from pyspark import SparkConf, SparkContext
con = SparkConf().setAppname("Read File")
sc = SparkContext.getOrCreate()
demo = sc.parallelize([1,2,3,4,5,6])
print(demo.collect())
# to run the code
>> spark-submit cdb.py
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
## Create a local StreamingContext with two working thread and batch interval of 1 seco$
sc = SparkContext()
ssc = StreamingContext(sc, 10)
# Create a DStream that will connect to hostname:port, like localhost:9999
lines = ssc.socketTextStream("localhost", 9999)
# Split each line into words
words = lines.flatMap(lambda line: line.split(" "))
# Count each word in each batch
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.pprint()
ssc.start() # Start the computation
ssc.awaitTermination() # Wait for the computation to terminate
>> nc -lk 9999
write any message here and press enter
# Databricks notebook source
# Picking up live data
import pyspark
from pyspark import SparkConf, SparkContext
from pyspark.streaming import StreamingContext
# COMMAND ----------
conf = SparkConf().setAppName("File streaming")
sc = SparkContext.getOrCreate(conf=conf)
# COMMAND ----------
# 10 sec streaming gap
ssc = StreamingContext(sc,10)
# COMMAND ----------
rdd = ssc.textFileStream("/FileStore/tables/")
# COMMAND ----------
rdd = rdd.map(lambda x: (x,1))
rdd = rdd.reduceByKey(lambda x,y: x+y)
rdd.pprint()
# COMMAND ----------
# 100000 second till
ssc.start()
ssc.awaitTerminationOrTimeout(100000)
- Developed by yahoo
- convert set of instruction to map reduce job
- to visualize data we can go with pig
- own lang that is pig latin
- PIG has two parts: Pig Latin, the language and the pig runtime, for the execution environment. You can better understand it as Java and JVM
- 10 line of pig latin = approx. 200 lines of Map-Reduce Java code
- prefered for ETL related stuffs(Pig Latin is one of the best scripting language to support the ETL process. It shows how to extract huge amount of data from a data source, transform the data so as to perform querying and also do the analysis jobs, and store back the end resultant data set onto a target destination database)
- In PIG, first the load command, loads the data. Then we perform various functions on it like grouping, filtering, joining, sorting, etc. At last, either you can dump the data on the screen or you can store the result back in HDFS.
>> mkdir pig
>> cd pig/
>> wget https://downloads.apache.org/pig/pig-0.17.0/pig-0.17.0.tar.gz
>> tar -xvf pig-0.17.0.tar.gz
>> cd
>> nano .bashrc
Add this in bottom of bachrc
____________
#JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
#Apache Pig Environment Variables
export PIG_HOME=/home/hiberstack/pig/pig-0.17.0
export PATH=$PATH:/home/hiberstack/pig/pig-0.17.0/bin
export PIG_CLASSPATH=$HADOOP_HOME/conf
export PIG_HOME=/home/ubh01/pig/pig-0.17.0
export PATH=$PATH:/home/ubh01/pig/pig-0.17.0/bin
export PIG_CLASSPATH=$HADOOP_HOME/conf
#JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
____________
# save ctrl + x and than Y
>> source .bashrc
# to check
>> pig -version
When we start Apache Pig, it opens a grunt shell. We can start Apache Pig in 2 execution modes as below
(a) Local Mode: In Local mode, the execution of Pig commands will be performed on the local file system. Files will be read and written from and into the local file system only rather than HDFS. We can start Pig in Local Mode with the below command
pig -x local
(b) MapReduce Mode: In this mode, the Pig commands will be executed on the files present on HDFS. The file will be read from and written into HDFS. This is the default mode of Pig. We can start Pig in MapReduce Mode with the below commands
pig
OR
pig -x mapreduce
- Map ex-: ['name'#'bob', 'age'#55]
- Tuple ex-: ('bob', 55)
- Bag ex-: {('bob', 55), ('sally', 52), ('john', 25)}
- Atoms ex-: datatype like int, char, float and string etc.
grunt> student = load '/home/ubh01/Desktop/StudentData.csv' using PigStorage(',') as (age: int, gender:chararray, name:chararray, course:chararray, roll:chararray, marks:int, email:chararray);
grunt> dump student
grunt> details = foreach student generate roll,name,age,gender;
# similar to select(roll,name,age,gender)
grunt> dump details
grunt> female = filter details by gender == 'Female';
grunt> female = filter details by gender == 'Female' and age == 28;
grunt> rollorder = order details by roll asc;
grunt> rollorder = order details by roll desc;
grunt> rollorder = order details by roll;
grunt> store rollorder into '/home/ubh01/Desktop/rollorderkarthick' using PigStorage(',');
grunt> store rollorder into '/home/ubh01/Desktop/rollorderkarthick' using PigStorage(':');
# you can use the below command to load data without schema
grunt> store rollorder into '/home/ubh01/Desktop/rollorderkarthick' using PigStorage(',','-schema');
grunt> karthick = load '/home/ubh01/Desktop/rollorderkarthick/part-r-00000' using PigStorage(',');
grunt> dump karthick
grunt> grouped = GROUP student by course;
grunt> dump grouped
- Streaming of data
Consist of three things-:
- Source-: which convert input to flume event
- channel-: through which mgs passed
- Sink-: Destination like hdfs or local file system
# file name write.sh
#!/bin/bash
rm logfile.log
i=0
while :
do
echo "Hadoop in Real World Developer $i" >> logfile.log
i=`expr $i + 1`
echo "sleeping for 5 seconds..."
sleep 5
done
# Flume Components
agent.sources = tail-source
agent.sinks = hdfs-sink
agent.channels = memory-channel
# Source
agent.sources.tail-source.type = exec
agent.sources.tail-source.command = tail -F logfile.log
agent.sources.tail-source.channels = memory-channel
# Define a sink that outputs to local file.
agent.sinks.hdfs-sink.type = hdfs
agent.sinks.hdfs-sink.hdfs.path = /flume/simple
agent.sinks.hdfs-sink.hdfs.fileType = DataStream
agent.sinks.hdfs-sink.channel = memory-channel
# Channels
agent.channels.memory-channel.type = memory
>> sh write.sh
>> flume-ng agent --conf /home/ubh01/flume/simple/ -f /home/ubh01/Desktop/simple/simple-flume.conf -Dflume.root.logger=DEBUG,console -n agent
>> hadoop fs -ls /
and to print
>> hadoop fs -cat /flume/simple/FlumeData.1653455264626

Apache Nifi link
- Apache NiFi is a real time data ingestion platform, which can transfer and manage data transfer between different sources and destination systems. It supports a wide variety of data formats like logs, geo location data, social feeds, etc. It also supports many protocols like SFTP, HDFS, and KAFKA, etc. This support to wide variety of data sources and protocols making this platform popular in many IT organizations.
- Provide a web based user Interface
- Drag and Drop
- Data ingestion is the process of obtaining and importing data for immediate use or storage in a database.
- Flowfiles = Content + attribute(kv pair)
- Flowfiles use by nifi processor to process the data
- Data ingestion is the process of transporting data from one or more sources to a target site for further processing and analysis.
- Apache NiFi is an ETL tool with flow-based programming that comes with a web UI built to provide an easy way (drag & drop) to handle data flow in real-time. It also supports powerful and scalable means of data routing and transformation, which can be run on a single server or in a clustered mode across many servers.