Parameters defining kernels
This Section describes the parameters in the C++ class HyPas which define the OpenCL GEMM kernel strings. A HyPas object is defined by 27 parameters. An example is,
HyPas hyperparameters
{{{"MIC1_PAD1_PLU1_LIW1_MIW1_WOS0_VEW1",
"MIC2_PAD2_PLU0_LIW0_MIW1_WOS0_VEW4",
"UNR16_GAL2_PUN1_ICE1_IWI1_SZT0_NAW64_UFO0_MAC64_SKW11_AFI1_MIA0_MAD0"}}};The construction above involves three strings. The first two define parameters specific to matrices A and B respectively, we refer to these as the chiral parameters. The third string defines parameters which are not symmetrical between A and B.
Before we jump into enumerating the parameters, we present definitions which will be needed to understand them, and give an overview of the basic GEMM algorithm.
-
A load tile is a rectangular region of
A(B) which a workgroup (a group of workitems, or threads) loads from global memory into local memory. Load tiles are illustrated in red and yellow in the next figure. -
A macro tile is a rectangular region of
Cwhich a workgroup works on. A macro tile is highlighted in the following figure, in peppermint green.

At a high level, the algorithm works as follows. Workgroups sequentially load the load tiles needed for their macro tile from global memory into local memory. From local memory, each thread in the workgroup then loads some elements into private memory (registers) and does the multiplications required. Finally scaling is done with alpha and beta and the result is written back to C in global memory. This tried-and-tested approach to implementing GEMM seems to have first been used by Volkov, V. and Demmel, J. W. (2008).
(one for A and one for B) is the micro tile length. This is the number of elements of C in the A (B) direction a thread will work on. The total number of elements of C a thread works on is the product of the 2 MICs, that is MIC-A.MIC-B. Each thread is allocated registers (private memory) of size MIC-A + MIC-B + MIC-A.MIC-B, where the third term are registers used to accumulate the outer product of the first two. Register memories are illustrated in the following figure

(one for A and one for B) is the padding applied to a load tile in local data memory (LDS). This is illustrated in the figure below. The > s in the figure denote coalesced memory direction.

(one for A and one for B) load parallel to unroll ? (YES or NO) This controls whether a thread loads elements from A (B) parallel or perpendicular to the unroll direction (unroll direction = k direction). This is illustrated in the next figure.
(one for A and one for B) loads are inter-woven ? (YES or NO) This controls whether the elements that a thread loads from global memory (from A and B) are inter-woven with other threads, or if the elements loaded are contiguous in the matrix. This is illustrated in the following figure. Suppose there are 16 threads loading a tile (of A or B with UNR = 4 and macro = 8). That means loading 2 elements for each thread.
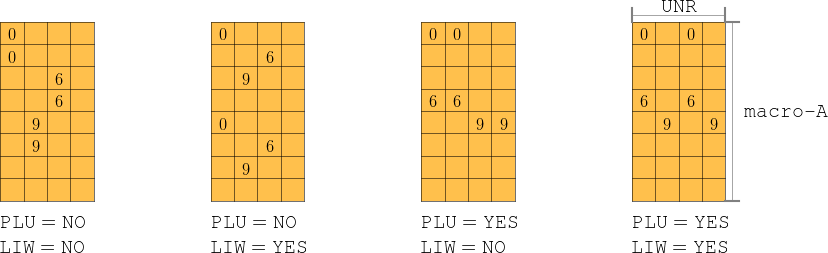
(one for A and one for B) micro inter-woven? (YES or NO) This controls whether the elements of C which a thread processes are inter-woven or contiguous in C, as illustrated in the following figure.

(one for A and one for B) workspace type. This is one of UNUSED, COPY and NFORM. UNUSED indicates an in-place GEMM, where elements are loaded directly from A (B) to LDS. COPY indicates that elements are copied from A (B) retaining the same overall layout (transposes are unchanged) except from an increases leading dimension stride ldA (ldB). This can help when the leading dimension stride has a large power of 2 as a factor. NFORM is the "row-within-column" format used in
Matsumoto et al., (2012) .
(one for A and one for B) vector width. When loading from global to LDS, the vector width can be sometimes be set to 2 or 4 as opposed to the default 1.
unroll length. The number of elements of C that a workgroup loads into LDS at a time. This must be the same for A and B, as the loaded load tiles from A and B are then multiplied together. UNR is illustrated in the first figure.
group allocation. This controls how workgroup IDs are mapped to macro tiles in C. GAL is one of BYROW, BYCOL and SUCOL. If it is BYROW, workgroups are mapped row-by-row. If it is BYCOL, workgroups are mapped column-by-column. Otherwise if it is SUCOL, workgroups are mapped by blocks within super-columns. This is illustrated in the figure below.

pragma unroll. If this is YES then #pragma unroll is inserted liberally around most for-loops.
number of workitems (threads) per C element. The standard GEMM algorithm has each element of C processed by 1 thread, but it is possible to divide work in the k-direction between threads which then write their results to C atomically when complete. In the first figure, if red and yellow unroll tiles are processed by separate work groups, then ICE is 1. The idea was described in Agarwal et al.
(1995) and is used in the ISAAC library.
inter-weave the ICE (above). This describes, when ICE > 1, how work in the k-direction is divided between threads. if IWI is YES, then the work is divided at a granularity of UNR. In other words, if IWI is YES, workgroup regions are inter-woven. In the first figure IWI is YES. If IWI is NO then threads process contiguous sections of C, so in figure 1 a first workgroup would process the first the unrolls and a second workgroup would process unrolls 4 (red), 5 (yellow) and 6 (red).
use size_t. If YES, then all integer types appearing in the OpenCL kernel string will be u_long. This parameter is more for debugging, SZT is never YES for optimal performance.
controls the super-column width when GAL is SUCOL. If GAL is not SUCOL, NAW has no effect. NAW is the number of work-groups in a block.
unroll for offset. If UFO is YES, work-groups are shifted in the unroll-direction by an amount Y0, which is dependent on their position in C (row and column). This means that the first load tiles are outside of C by an amount Y0. This edge case is handled in the same way as when UNR is not a multiple of k, as described HERE : TODO link to edge cases page. In general when UFO is ON performance is worse, but occasionally it helps. Y0 = (13 * ida + 7 * idb)% UNR where ida and idb are the workgroups coordinates in the C grid.

number of macro-tile threads. This is exactly local_worksize in OpenCL. In the running example on this page it is 16, in practice performance is normally best when it is 64 or 256, at least on a Fiji Nano GPU.
skewness. This describes how micro-tiles (threads) are packed into the macro-tile. More specifically, the elongation of work-groups. Suppose MAC is 64. This could be made up of a 1x64 or 2x32 or 4x16 or 8x8 or 16x4 or 32x2 or 64x1 grid of threads. We choose an integer skw0 to correspond the square grid, 8x8 is this example. When MAC is a squared integer, like 16 or 64, macro tile size is determined as follows:
macro-A = mic-A . sqrt(MAC) . 2^(skw0/SKW)
macro-B = mic-B . sqrt(MAC) . 2^(SKW/skw0).
A first. This determines whether loops over A and B should be over the A or B dimension first, and whether loads from global memory should have A before B. In theory this should not make a difference, but we have found that "shaking up the compiler" can sometimes help.
micro A first. This controls whether threads are mapped to micro tiles by row (A) or column (B).
mad operation. if YES, then the inner-most looks like c = mad(a, b, c) otherwise it looks like c += a*b