Sequence Model Goals
The term sequence refers to the list of datasets, instrument configurations and offset positions involved in collecting data for a Gemini observation. Each individual dataset and its corresponding configuration is a single sequence step. The sequence is represented internally by a software model called the sequence model. We use the sequence model for many purposes in the Observatory Control System and in its client applications like the Observing Tool. For example, we need the sequence model to calculate planned time, perform Phase 2 validation checks, and decide how to set up "smart" GCal Unit arc and flat calibrations.
Unfortunately the existing sequence model suffers from serious flaws which make it difficult to work with and maintain. Model limitations have been holding back a number desirable features for more than a decade. To get sense of what we mean by "flaws" there is no better example than the fragility issue that every Gemini observer knows well. In particular, because the sequence is modeled internally as a collection of loops, once it has started executing it is difficult to change. Even adding a few extra steps at the end to get better signal-to-noise can be challenging. The reason is that any change to a loop alters the entire sequence, even if some steps have already been executed. For example, consider a simple sequence configured as a series of offset positions:
- Offset (ABBA)
- Observe 2X
When unrolled into a series of steps, that will produce 8 datasets: A, A, B, B, B, B, A, A. Now assume that the first 3 datasets have been collected: A, A, B. If we change the "Observe 2X" to "Observe 3X" we should then generate 12 datasets: A, A, A, B, B, B, B, B, B, A, A, A yet already the 3rd dataset we collected doesn't match the sequence (it is at position B instead of A).
This may not be a very realistic example but it should be easy to see how the existing representation is fragile. Great pains were taken in the implementation of Smart GCal for a similar reason -- the mapping of instrument configurations to required calibration configurations can change after the corresponding calibration steps have already been executed. We therefore attempt to record executed calibration step configurations in an immutable list but the implementation has proven to be buggy.
The current sequence model is also slow because each time we need to know what the sequence will produce we must "unroll" the loops. This is done repeatedly in the OT and is a contributing factor to the performance issues surrounding large programs.
In order to solve all of these issues and permit new features like combining acquisition and science sequences in a single observation, we need to change the way that sequences are modeled internally. Specifically we plan to switch to a flattened list of sequence steps instead of a collection of nested loops. This may sound like a trivial update but it will touch 15 years of code that have been built with the existing model. There are a number of considerations to take into account, such as the impact on the size of the data sent between the OT and an ODB, how to handle synchronization conflicts, etc.
From our point of view as software engineers, the main driver for this work is to improve the model and make it easier to maintain and extend. Nevertheless, the purpose of this document isn't to cover the technical details of how the implementation will work but rather to look at the possibilities that will be unlocked by a new sequence model. The idea is to ensure that everyone is aware of and in agreement with our vision for the changes that will be implemented over the coming years. This is important because an upfront discussion can help guide technical decisions about how to represent the sequence and the types of operations the model must support. For example if there is a feature that we feel is important to the end user that after discussion turns out to be misguided, removing it can save complications in the model that would have otherwise been needed. Alternatively, we might be missing critical features that require rethinking how we model sequences.
This document contains initial thoughts about changes to the sequence model and the impact they could have on the UI. The ideas are still pretty rough but our hope is that this will provide a starting point for discussing and refining the goals.
Both in the program model and in its representation in the Observing Tool, we plan to flatten the entire sequence hierarchy into a single node. In particular, we will combine instrument, obslog, sequence, and at least part of the seqexec UI into a single "Sequence" node. The Target and Conditions nodes would remain separate. You can think about the individual sequences as sharing the same target and conditions. Eventually we will allow multiple sequence nodes per observation (for example to combine acquisition and science sequences).

Internally each sequence becomes a simple list of steps, so there is no need to generate it each time it is needed. The UI will be a challenge, as is detailed in the next section.
Allowing multiple sequences per observation is a fundamental change and a number of issues will need to be worked out to make it a reality. For example,
- Sequences would become schedulable entities in this model and would need to be referred to individually.
- Dataset labels might need to be updated to take this into account.
- This change will impact the seqexec and QPT obviously, etc. etc.
Still, there is great benefit to switching to a flattened model even before we allow multiple sequences per observation. We believe the work can be split into a number of phases each of which could come with an accompanying release:
-
Flat sequence model and basic sequence editing. The OT will present a table view of the sequence, allowing individual steps to be edited independently. It should be possible to insert new steps where needed and delete steps that are no longer desired. We must provide controls to edit multiple steps simultaneously. A corresponding nested-loop view editor should be provided as well for situations in which it is easier to envision the sequence that way.
-
Combine obslog and sequence node. The idea is to show executed steps in the same view as the editor for upcoming steps. There should be no need to switch between different nodes in order to set the QA State or comment on datasets.
-
Multiple sequences per observation. There should be no limit to the number of sequences that an observation may have. The most common use case for this is expected to be sharing target and conditions information for acquisition and science sequences.
-
Seqexec controls. Basic sequence execution should be possible directly in the OT, obviating the need to switch back and forth between an OT and a seqexec.
In the sections that follow, we will present UI ideas that assume all these changes are to be incorporated. When we actually start to work on this project though, we would begin with just enough to flatten the sequence model and do basic sequence editing. A release with just those changes could be made before moving on to later phases.
Roughly, a "Sequence" node could be divided into 3 areas representing the past, present, and future:
-
Sequence Log - This is today's "Observing Log". It is an immutable view of any steps that have already been completed along with controls for setting QA State and adding comments. The Sequence Log appears once you first slew to the target or in general whenever an event from the seqexec is received for that sequence. As datasets are executed, they are pulled up from the planning area below to become immutable entries (as far as the config is concerned) in the log. For each dataset it shows the label that is assigned, the FITS file name, the QA state, comment (if any) and then the config. Here we could provide options for downloading datasets from the Gemini Science Archive as well for the convenience of PIs. In fact, it should even be possible to automatically download datasets as they become available if desired.
-
Sequence Execution - The current dataset being observed (if any). Again this is an immutable view because it represents the dataset being observed at the moment. Simple seqexec controls for pausing, aborting, resuming, etc. can eventually be incorporated as well. Probably we should include a one-click mechanism to duplicate the dataset being executed into the top of the planning area below.
-
Sequence Planning - This is where remaining steps are configured. Since these steps have not been executed, there is no need to make them immutable, even after the sequence has been started. (Until we have tight integration with the seqexec though, we will likely need to freeze editing until the sequence is paused or completed. Otherwise we might allow a step to be edited that is currently under execution.) Truly static values (like the MOS pre-imaging flag) should be presented differently somehow and not be editable once the sequence has started. Whereas today Phase 2 checks are indicated at the root sequence node, we can place any warnings or errors directly in the corresponding steps. As part of the eventual seqexec UI integration, "breakpoints" could be configured here as well in order to automatically pause the sequence when reached.
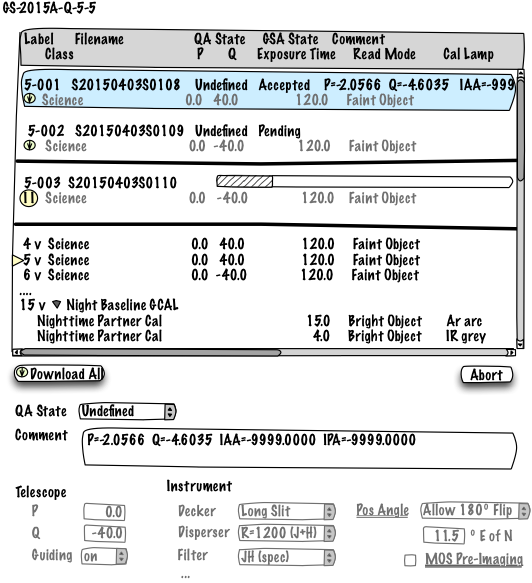
In this mockup, the first two datasets are part of the log of executed steps. These are followed by the single dataset that is currently executing. There is a yellow pause button to indicate seqexec controls beside the current dataset. For the first three datasets the configuration is shown in grey to indicate that it cannot be edited. The "QA State" and "Comment" options would appear when you select an executed step, as shown in the figure.
Only steps in the planning section at the bottom (steps 4 and beyond in the picture) could be rearranged or edited. The yellow triangle in the picture is meant to indicate that a breakpoint has been added at that step. Note that the telescope offset and instrument configurations are shown as simple property sheets. The idea is to present a uniform interface rather than developing custom instrument layouts for each instrument. Configuration that is shared across all steps is underlined, as is the case for the position angle and the MOS Pre-Imaging flag.
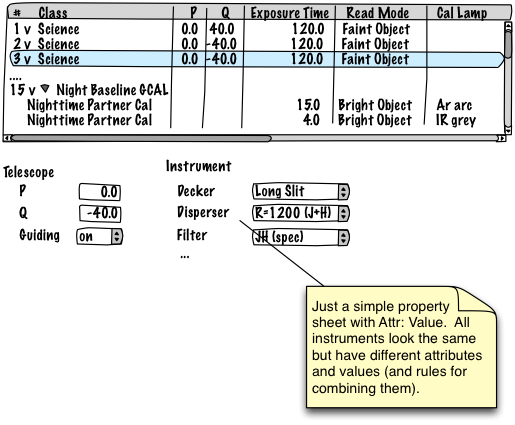
Sequence Planning would have two views / editors. A sequence table somewhat like the one we enjoy today and a loop hierarchy editor as well. It should be possible to go back and forth between the two views.
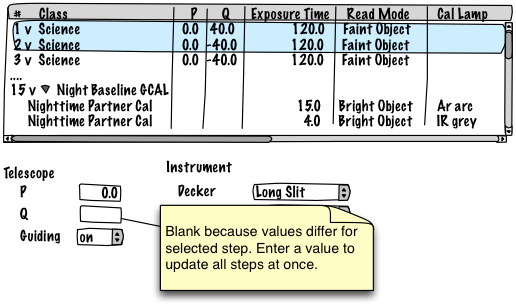
The sequence table shows a row per dataset. Columns appear for every parameter that differs across the sequence. Parameters that never change are not shown in the table, but the user can see the values in the property sheet displayed for any selected dataset.
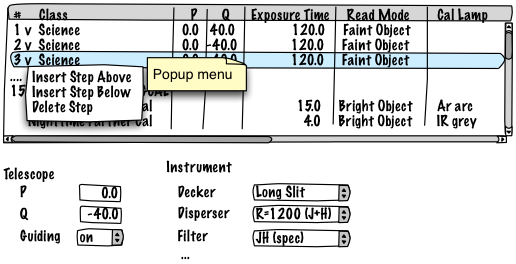
A major goal is to make arbitrary sequence editing possible. The OT must support inserting and deleting rows at-will anywhere. It should be possible to duplicate a row or rows, and to drag/drop to rearrange.
Multi-select rows and the editor shows the user values common across all selected steps and permits changes for all steps at once.
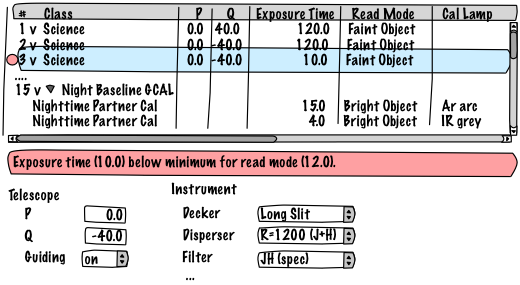
Phase 2 checking will be performed at all steps with any problems clearly indicated at the corresponding step.
Initially creating a sequence or performing major edits may be easier to do with a nested-loop view like we have today.
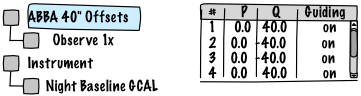
It should be possible to map back and forth, though there will sometimes be multiple ways to arrange loops that generate the same sequence. For partially executed sequences, the loop structure might get a bit convoluted since the already executed steps would not be included. Note this view is not stored anywhere and doesn't appear in the science program tree view. Rather, the user would switch between the table view and the nested loop view, which would be generated by analyzing any remaining steps.
The UI doodles above depict a "Night Baseline GCAL" row and show how that expands to two steps. The expansion won't actually be stored in the model though, because it can change at any point in the future. The OT simply reveals the mapping at the time the sequence is displayed. Once a smart calibration is started, the notion of "smart" goes away and the current state of the expansion is kept as normal calibration sequence steps. Similarly, if the user should edit a smart GCAL expansion (multi-step or not) it also loses its intelligence and becomes an ordinary manual calibration step. With these changes to the model, it becomes possible to add support for smart darks which should work in a similar way.