
Lhotse is a Python library aiming to make speech and audio data preparation flexible and accessible to a wider community. Alongside k2, it is a part of the next generation Kaldi speech processing library.
- (Interspeech 2023) Tutorial notebook
- (Interspeech 2023) Tutorial slides
- (Interspeech 2021) Recorded lecture (3h)
- Attract a wider community to speech processing tasks with a Python-centric design.
- Accommodate experienced Kaldi users with an expressive command-line interface.
- Provide standard data preparation recipes for commonly used corpora.
- Provide PyTorch Dataset classes for speech and audio related tasks.
- Flexible data preparation for model training with the notion of audio cuts.
- Efficiency, especially in terms of I/O bandwidth and storage capacity.
We currently have the following tutorials available in examples directory:
- Basic complete Lhotse workflow
- Transforming data with Cuts
- WebDataset integration
- How to combine multiple datasets
- Lhotse Shar: storage format optimized for sequential I/O and modularity
Check out the following links to see how Lhotse is being put to use:
- Icefall recipes: where k2 and Lhotse meet.
- Minimal ESPnet+Lhotse example:
Like Kaldi, Lhotse provides standard data preparation recipes, but extends that with a seamless PyTorch integration through task-specific Dataset classes. The data and meta-data are represented in human-readable text manifests and exposed to the user through convenient Python classes.
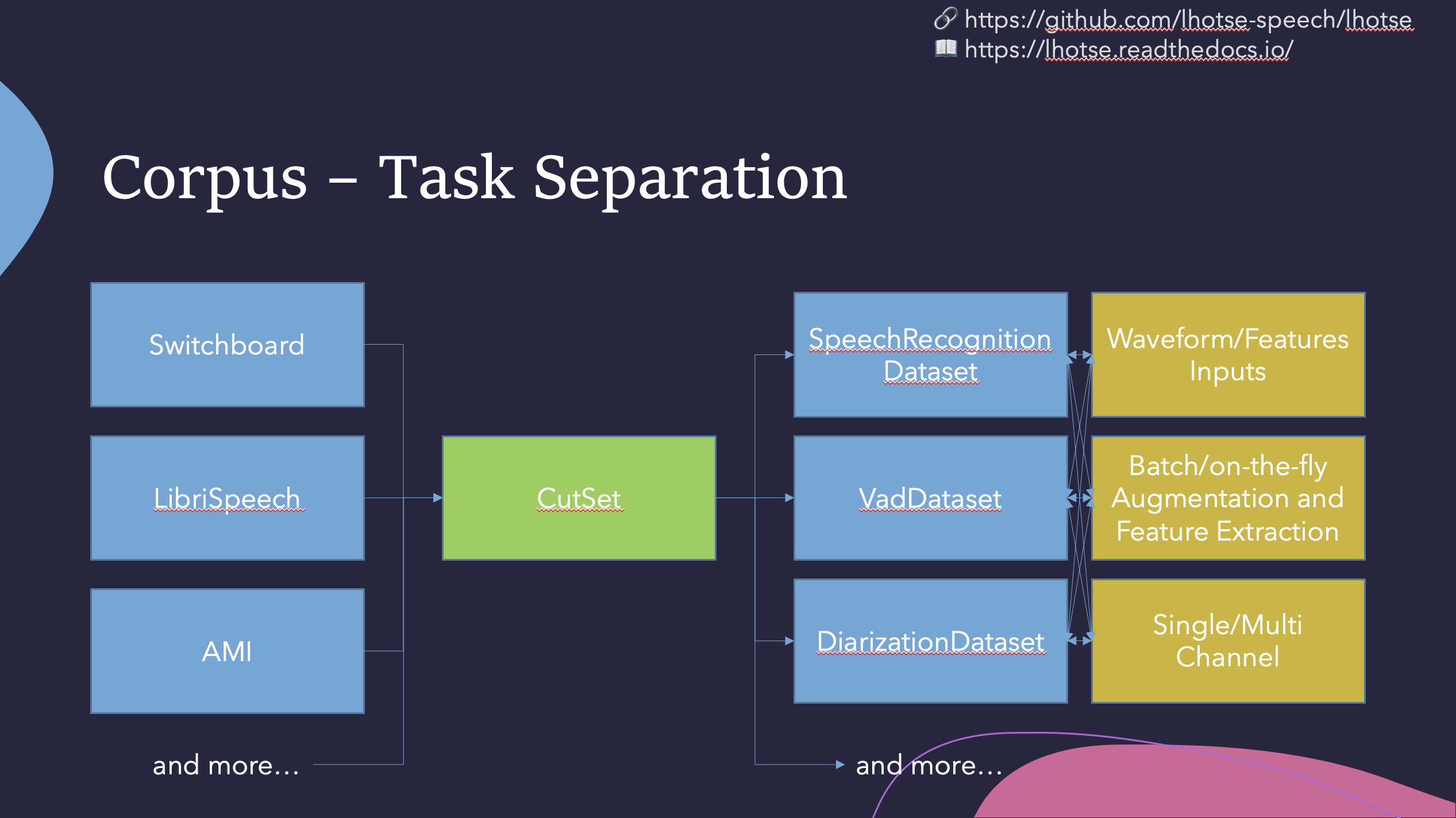
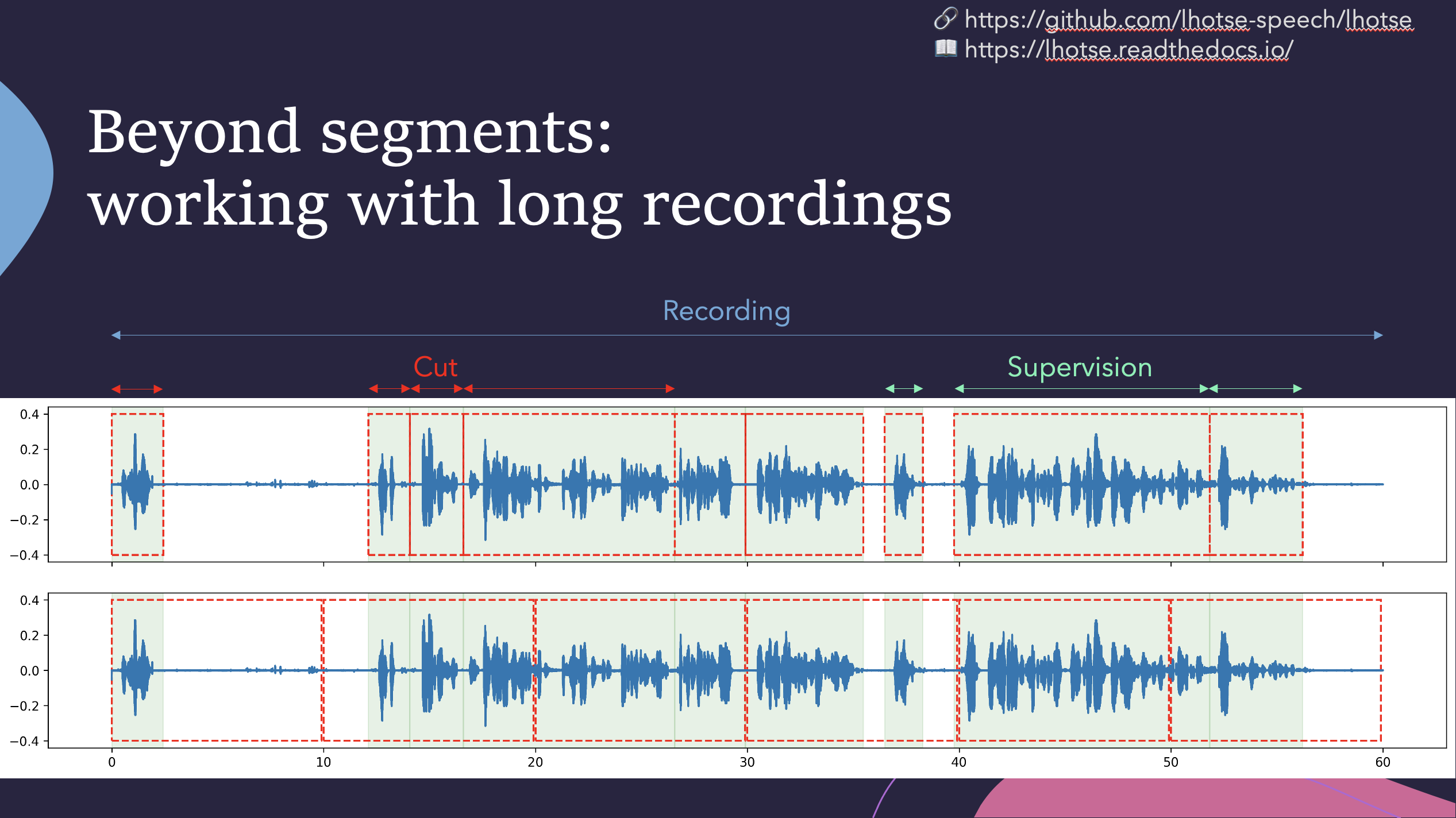
Lhotse introduces the notion of audio cuts, designed to ease the training data construction with operations such as mixing, truncation and padding that are performed on-the-fly to minimize the amount of storage required. Data augmentation and feature extraction are supported both in pre-computed mode, with highly-compressed feature matrices stored on disk, and on-the-fly mode that computes the transformations upon request. Additionally, Lhotse introduces feature-space cut mixing to make the best of both worlds.
Lhotse supports Python version 3.7 and later.
Lhotse is available on PyPI:
pip install lhotse
To install the latest, unreleased version, do:
pip install git+https://github.com/lhotse-speech/lhotse
For development installation, you can fork/clone the GitHub repo and install with pip:
git clone https://github.com/lhotse-speech/lhotse
cd lhotse
pip install -e '.[dev]'
pre-commit install # installs pre-commit hooks with style checks
# Running unit tests
pytest test
# Running linter checks
pre-commit run
This is an editable installation (-e option), meaning that your changes to the source code are automatically
reflected when importing lhotse (no re-install needed). The [dev] part means you're installing extra dependencies
that are used to run tests, build documentation or launch jupyter notebooks.
Lhotse uses several environment variables to customize it's behavior. They are as follows:
LHOTSE_REQUIRE_TORCHAUDIO- when it's set and not any of1|True|true|yes, we'll not check for torchaudio being installed and remove it from the requirements. It will disable many functionalities of Lhotse but the basic capabilities will remain (including reading audio withsoundfile).LHOTSE_AUDIO_DURATION_MISMATCH_TOLERANCE- used when we load audio from a file and receive a different number of samples than declared inRecording.num_samples. This is sometimes necessary because different codecs (or even different versions of the same codec) may use different padding when decoding compressed audio. Typically values up to 0.1, or even 0.3 (second) are still reasonable, and anything beyond that indicates a serious issue.LHOTSE_AUDIO_BACKEND- may be set to any of the values returned from CLIlhotse list-audio-backendsto override the default behavior of trial-and-error and always use a specific audio backend.LHOTSE_AUDIO_LOADING_EXCEPTION_VERBOSE- when set to1we'll emit full exception stack traces when every available audio backend fails to load a given file (they might be very large).LHOTSE_DILL_ENABLED- when it's set to1|True|true|yes, we will enabledill-based serialization ofCutSetandSampleracross processes (it's disabled by default even whendillis installed).LHOTSE_LEGACY_OPUS_LOADING- (=1) reverts to a legacy OPUS loading mechanism that triggered a new ffmpeg subprocess for each OPUS file.LHOTSE_PREPARING_RELEASE- used internally by developers when releasing a new version of Lhotse.TORCHAUDIO_USE_BACKEND_DISPATCHER- when set to1and torchaudio version is below 2.1, we'll enable the experimental ffmpeg backend of torchaudio.AIS_ENDPOINTis read by AIStore client to determine AIStore endpoint URL. Required for AIStore dataloading.RANK,WORLD_SIZE,WORKER, andNUM_WORKERSare internally used to inform Lhotse Shar dataloading subprocesses.READTHEDOCSis internally used for documentation builds.
Other pip packages. You can leverage optional features of Lhotse by installing the relevant supporting package:
torchaudioused to be a core dependency in Lhotse, but is now optional. Refer to official PyTorch documentation for installation.pip install lhotse[kaldi]for a maximal feature set related to Kaldi compatibility. It includes libraries such askaldi_native_io(a more efficient variant ofkaldi_io) andkaldifeatthat port some of Kaldi functionality into Python.pip install lhotse[orjson]for up to 50% faster reading of JSONL manifests.pip install lhotse[webdataset]. We support "compiling" your data into WebDataset tarball format for more effective IO. You can still interact with the data as if it was a regular lazy CutSet. To learn more, check out the following tutorial:pip install h5pyif you want to extract speech features and store them as HDF5 arrays.pip install dill. Whendillis installed, we'll use it to pickle CutSet that uses a lambda function in calls such as.mapor.filter. This is helpful in PyTorch DataLoader withnum_jobs>0. Withoutdill, depending on your environment, you'll see an exception or a hanging script.pip install aistoreto read manifests, tar fles, and other data from AIStore using AIStore-supported URLs (setAIS_ENDPOINTenvironment variable to activate it). See AIStore documentation for more details.pip install smart_opento read and write manifests and data in any location supported bysmart_open(e.g. cloud, http).pip install opensmilefor feature extraction using the OpenSmile toolkit's Python wrapper.
sph2pipe. For reading older LDC SPHERE (.sph) audio files that are compressed with codecs unsupported by ffmpeg and sox, please run:
# CLI
lhotse install-sph2pipe
# Python
from lhotse.tools import install_sph2pipe
install_sph2pipe()
It will download it to ~/.lhotse/tools, compile it, and auto-register in PATH. The program should be automatically detected and used by Lhotse.
We have example recipes showing how to prepare data and load it in Python as a PyTorch Dataset.
They are located in the examples directory.
A short snippet to show how Lhotse can make audio data preparation quick and easy:
from torch.utils.data import DataLoader
from lhotse import CutSet, Fbank
from lhotse.dataset import VadDataset, SimpleCutSampler
from lhotse.recipes import prepare_switchboard
# Prepare data manifests from a raw corpus distribution.
# The RecordingSet describes the metadata about audio recordings;
# the sampling rate, number of channels, duration, etc.
# The SupervisionSet describes metadata about supervision segments:
# the transcript, speaker, language, and so on.
swbd = prepare_switchboard('/export/corpora3/LDC/LDC97S62')
# CutSet is the workhorse of Lhotse, allowing for flexible data manipulation.
# We create 5-second cuts by traversing SWBD recordings in windows.
# No audio data is actually loaded into memory or stored to disk at this point.
cuts = CutSet.from_manifests(
recordings=swbd['recordings'],
supervisions=swbd['supervisions']
).cut_into_windows(duration=5)
# We compute the log-Mel filter energies and store them on disk;
# Then, we pad the cuts to 5 seconds to ensure all cuts are of equal length,
# as the last window in each recording might have a shorter duration.
# The padding will be performed once the features are loaded into memory.
cuts = cuts.compute_and_store_features(
extractor=Fbank(),
storage_path='feats',
num_jobs=8
).pad(duration=5.0)
# Construct a Pytorch Dataset class for Voice Activity Detection task:
dataset = VadDataset()
sampler = SimpleCutSampler(cuts, max_duration=300)
dataloader = DataLoader(dataset, sampler=sampler, batch_size=None)
batch = next(iter(dataloader))The VadDataset will yield a batch with pairs of feature and supervision tensors such as the following - the speech
starts roughly at the first second (100 frames):
