Introduction
Goka is a compact yet powerful Go stream processing library for Apache Kafka that eases the development of scalable, fault-tolerant, data-intensive applications. Goka is a Golang twist of the ideas described in "I heart logs" by Jay Kreps and "Making sense of stream processing" by Martin Kleppmann.
This text introduces the Goka library and some of the rationale and concepts behind it. It also presents a simple example to help you get started.
At the core of any Goka application are one or more key-value tables representing the application state. Goka provides building blocks to manipulate such tables in a composable, scalable, and fault-tolerant manner. All state-modifying operations are transformed in event streams, which guarantee key-wise sequential updates. Read-only operations may directly access the application tables, providing eventually consistent reads.

Goka encourages the developer to decompose the application into microservices using three different components: emitters, processors, and views. The figure below depicts the abstract application again, but now showing the use of these three components together with Kafka and the external API.
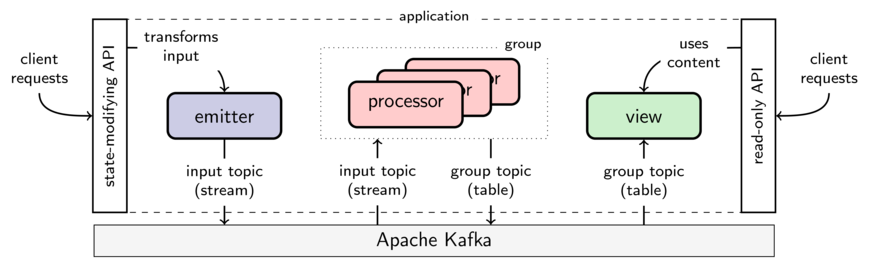
Emitters. Part of the API offers operations that can modify the state. Calls to these operations are transformed into streams of messages with the help of an emitter, i.e., the state modification is persisted before performing the actual action as in the event sourcing pattern. An emitter emits an event as a key-value message to Kafka. In Kafka's parlance, emitters are called producers and messages are called records. We employ the modified terminology to focus this discussion to the scope of Goka only. Messages are grouped in topics, e.g., a topic could be a type of click event in the interface of the application. In Kafka, topics are partitioned and the message's key is used to calculate the partition into which the message is emitted.
Processors. A processor is a set of callback functions that modify the content of a key-value table upon the arrival of messages. A processor consumes from a set of input topics (i.e., input streams). Whenever a message m arrives from one of the input topics, the appropriate callback is invoked. The callback can then modify the table's value associated with m's key.
Processor groups. Multiple instances of a processor can partition the work of consuming the input topics and updating the table. These instances are all part of the same processor group. A processor group is Kafka's consumer group bound to the table it modifies.
Group table and group topic. Each processor group is bound to a single table (that represents its state) and has exclusive write-access to it. We call this table the group table. The group topic keeps track of the group table updates, allowing for recovery and rebalance of processor instances as described later. Each processor instance keeps the content of the partitions it is responsible for in its local storage, by default LevelDB. A local storage in disk allows a small memory footprint and minimizes the recovery time.
Views. A view is a persistent cache of a group table. A view subscribes to the updates of all partitions of a group topic, keeping a local disk storage in sync with the table. With a view, one can easily serve up-to-date content of the group table via, for example, gRPC.
As we present next, the composability, scalability, and fault-tolerance aspects of Goka are strongly related to Kafka. For example, emitters, processors, and views can be deployed in different hosts and scaled in different ways because they communicate exclusively via Kafka. Before discussing these aspects though, we take a look at a simple example.
Let us create a toy application that counts how often users click on some button. Whenever a user clicks on the button, a message is emitted to a topic, called "user-clicks". The message's key is the user ID and, for the sake of the example, the message's content is a timestamp, which is irrelevant for the application. In our application, we have one table storing a counter for each user. A processor updates the table whenever such a message is delivered.
To process the user-clicks topic, we create a process() callback that takes two arguments (see the code sample below): the callback context and the message's content. Each key has an associated value in the processor's group table. In our example, we store an integer counter representing how often the user has performed clicks.
func process(ctx goka.Context, msg interface{}) {
var counter int64
if val := ctx.Value(); val != nil {
counter = val.(int64)
}
counter++
ctx.SetValue(counter)
fmt.Println("k:", ctx.Key(), "c:", counter, "m:", msg)
}To retrieve the current value of counter, we call ctx.Value(). If the result is nil, nothing has been stored so far, otherwise we cast the value to an integer. We then process the message by simply incrementing the counter and saving the result back in the table with ctx.SetValue(). We then print the key, the current count of the user, and the message's content.
Note that goka.Context is a rich interface. It allows the processor to emit messages into other stream topics using ctx.Emit(), read values from tables of other processor groups with ctx.Join() and ctx.Lookup(), and more.
The following snippet shows the code to define the processor group. goka.DefineGroup() takes the group name as first argument followed by a list of "edges" to Kafka. goka.Input() defines that process() is invoked for every message received from "user-clicks" and the message content is a string. Persist() defines that the group table contains a 64-bit integer for each user. Every update of the group table is sent to Kafka to the group topic, called "my-group-state" by default.
g := goka.DefineGroup(goka.Group("my-group"),
goka.Input(goka.Stream("user-clicks"), new(codec.String), process),
goka.Persist(new(codec.Int64)),
)The complete code as well as a description how to run the code can be found here. The example in this link also starts an emitter to simulate the users clicks and a view to periodically show the content of the group table.
Once applications are decomposed using Goka's building blocks, one can easily reuse tables and topics from other applications, loosening the application boundaries. For example, the figure below depicts two applications click-count and user-status that share topics and tables.
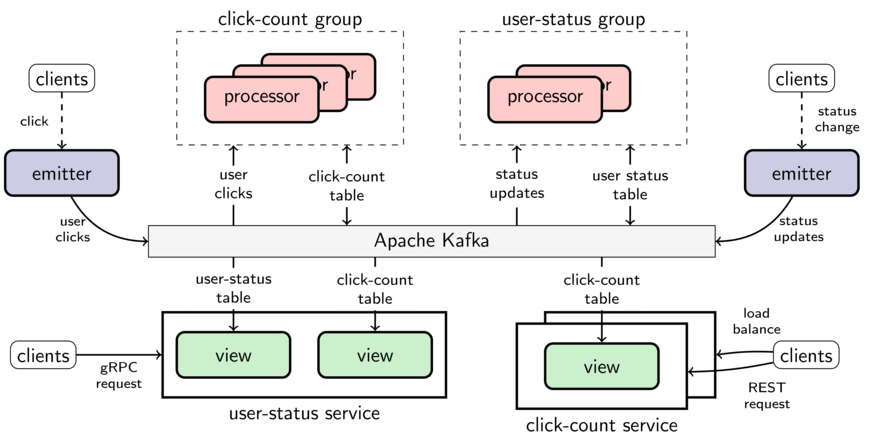
Click count. An emitter sends user-click events, whenever a user clicks on a specific button. The click-count processors count the number of clicks users have performed. The click-count service provides read access to the content of the click-count table with a REST interface. The service is replicated to achieve a higher availability and lower response time.
User status. The user-status processors keep track of the latest status message of each user in the platform – let's imagine our example is part of a social network system. An emitter is responsible for producing status update events whenever the user changes their status. The user-status service provides the latest status of the users (from user-status) joined with the number of clicks the user has performed (from click-count). For joining tables, a service simply instantiates a view for each of the tables.
Note that emitters do not have to be associated to any specific Goka application. They are often simply embedded in other systems just to announce interesting events to be processed on demand. Also note that as long as the same codecs are used to encode and decode messages, Goka applications can share streams and tables with Kafka Streams, Samza or any other Kafka-based stream processing framework or library.
Emitters. Emitters are rather simple components. They can be scaled by instantiating multiple of them whenever necessary. The limiting factor for emitters is the maximal load Kafka can take, which is dependent on the number of brokers available, the total number of partitions, the size of the messages, and the available network bandwidth.
Views. Views are slightly more complex. Views locally hold a copy of the complete table they subscribe. If one implements a service using a view, the service can be scaled by spawning another copy of it. Multiple views are eventually consistent. Nevertheless, one has to consider two potential resource constraints: First, each instance of a view consumes all partitions of a table and uses the required network traffic for that. Second, each view instance keeps a copy of the table in local storage, increasing the disk usage accordingly. Note that the memory footprint is not necessarily as large as the disk footprint since only values of keys often retrieved by the user are cached in memory by LevelDB.
Processors. Processors are scaled by increasing the number of instances in the respective processor groups. All input topics of a processor group are required to be co-partitioned with the group topic, i.e., the input topics and the group topic all have the same number of partitions and the same key range. That allows Goka to consistently distribute the work among the processor instances using Kafka's rebalance mechanism and grouping the partitions of all topics together and assigning these partition groups at once to the instances. For example, if a processor is assigned partition 1 of an input topic, then it is also assigned partition 1 of all other input topics as well as partition 1 of the group table.
Each processor instance only keeps a local copy of the partitions it is responsible for. It consumes and produces traffic only for those partitions. The traffic and storage requirements change, however, when a processor instance fails, because the remainder instances share the work and traffic of the failed one.
Emitters. Once an emitter successfully completes emitting a message, the message is guaranteed to be eventually processed by every processor group subscribing the topic. Moreover, if an emitter successfully emits two messages to the same topic/partition, they are processed in the same order by every processor group that subscribes to the topic.
Views. A view eventually sees all updates of the table it subscribes since the processor group emits a message for every group table modification into the group topic. The view may stutter, though, if the processor group reprocesses messages after a failure. If the view itself fails, it can be (re)instantiated elsewhere and recover its table from Kafka.
Processors. Each input message is guaranteed to be processed at least once. Being a Kafka consumer, Goka processors keep track of how far they have processed each topic partition. Whenever an input message is fully processed and the processor output is persisted in Kafka, the processor automatically commits the input message offset back in Kafka. If a processor instance crashes before committing the offset of a message, the message is processed again after recovery and causes the respective table update and output messages.
In case the crashed instance does not recover, the group rebalances, and the remainder processor instances are assigned the dangling partitions of the failed one. Each partition in Kafka is consumed in the same order by different consumers. Hence, the state updates are replayed in the same order after a recovery — even in another processor instance.
Goka is in active development and has much more to offer than described here, for example,
built-in performance monitoring and state query interfaces; and modularity with sane defaults: Goka employs sarama to access Kafka. Previous support for Confluent's go library has been removed. The local storage is by default implemented with LevelDB, but can be replaced with other storage libraries by bridgding them to the storage interface.
To get started, check the examples directory, and the documentation. See our extended example for several processor patterns used in our applications, including:
- key-wise stream-table joins, e.g., joining user actions with user profiles;
- cross-joins/broadcast-joins, e.g., joining user actions with a device table; and
- sending messages to other keys in the same group via a loopback topic.
Please, contact us via GitHub issues if you have questions or encountered a bug.