🙅 status: discontinued: Project is in maintenance mode.
This project is being continued by WordPress:
- WordPress/openverse-api: The Openverse API allows programmatic access to search for CC-licensed and public domain digital media.
For additional context see:


{kind=link}
The Creative Commons Catalog API ('cccatalog-api') is a system that allows programmatic access to public domain digital media. It is our ambition to index and catalog billions of Creative Commons works, including articles, songs, videos, photographs, paintings, and more. Using this API, developers will be able to access the digital commons in their own applications.
This repository is primarily concerned with back end infrastructure like datastores, servers, and APIs. The pipeline that feeds data into this system can be found in the cccatalog repository. A front end web application that interfaces with the API can be found at the cccatalog-frontend repository.
In the API documentation, you can find more details about the endpoints with examples on how to use them.
You need to install Docker (with Docker Compose), Git, and PostgreSQL client tools. On Debian, the package is called postgresql-client-common.
-
Run the Docker daemon
-
Open your command prompt (CMD) or terminal
-
Clone CC Catalog API
git clone https://github.com/creativecommons/cccatalog-api.git
- Change directory to CC Catalog API
cd cccatalog-api
- Start CC Catalog API locally
docker-compose up
- Wait until your CMD or terminal displays that it is starting development server at
http://0.0.0.0:8000/

-
Open up your browser and type
localhost:8000in the search tab -
Make sure you see the local API documentation

-
Open a new CMD or terminal and change directory to CC Catalog API
-
Still in the new CMD or terminal, load the sample data
./load_sample_data.sh
- Still in the new CMD or terminal, hit the API with a request
curl localhost:8000/v1/images?q=honey
- Make sure you see the following response from the API

Congratulations! You just run the server locally.
After executing docker-compose up (in Step 5), you will be running:
- A Django API server
- Two PostgreSQL instances (one simulates the upstream data source, the other serves as the application database)
- Elasticsearch
- Redis
- A thumbnail-generating image proxy
- ingestion-server, a service for bulk ingesting and indexing search data.
- analytics, a REST API server for collecting search usage data
If the API server container failed to start, there's a good chance that Elasticsearch failed to start on your machine. Ensure that you have allocated enough memory to Docker applications, otherwise the container will instantly exit with an error. Also, if the logs mention "insufficient max map count", increase the number of open files allowed on your system. For most Linux machines, you can fix this by adding the following line to /etc/sysctl.conf:
vm.max_map_count=262144
To make this setting take effect, run:
sudo sysctl -p
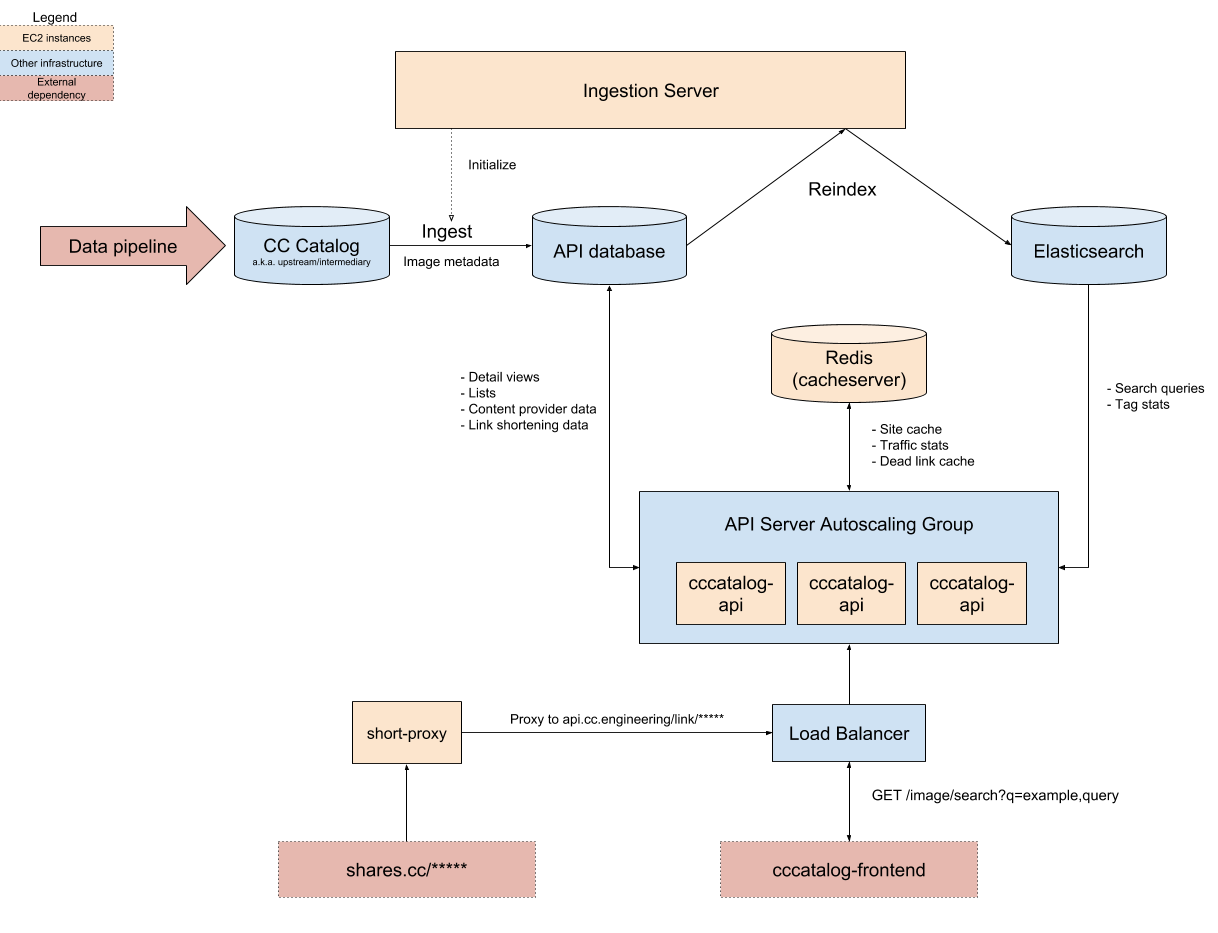
Search data is ingested from upstream sources provided by the data pipeline. As of the time of writing, this includes data from Common Crawl and multiple 3rd party APIs. Once the data has been scraped and cleaned, it is transferred to the upstream database, indicating that it is ready for production use.
Every week, the latest version of the data is automatically bulk copied ("ingested") from the upstream database to the production database by the Ingestion Server. Once the data has been downloaded and indexed inside of the database, the data is indexed in Elasticsearch, at which point the new data can be served up from the CC Catalog API servers.
- cccatalog-api is a Django Rest Framework API server. For a full description of its capabilities, please see the browsable documentation.
- ingestion-server is a service for downloading and indexing search data once it has been prepared by the CC Catalog.
- analytics is a Falcon REST API for collecting usage data.
You can check the health of a live deployment of the API by running the live integration tests.
- Change directory to CC Catalog API
cd cccatalog-api
- Install all dependencies for CC Catalog API
pipenv install
- Launch a new shell session
pipenv shell
- Run API live integration test
./test/run_test.sh
You can ingest and index some dummy data using the Ingestion Server API.
- Change directory to ingestion server
cd ingestion_server
- Install all dependencies for Ingestion Server API
pipenv install
- Launch a new shell session
pipenv shell
- Run the integration tests
python3 test/integration_tests.py
The API infrastructure is orchestrated using Terraform hosted in creativecommons/ccsearch-infrastructure. You can find more details on this wiki page.
You can view the custom administration views at the /admin/ endpoint.
Pull requests are welcome! Feel free to join us on Slack and discuss the project with the engineers on #cc-search.
You are welcome to take any open issue in the tracker labeled help wanted or good first issue; there's no need to ask for permission in advance. Other issues are open for contribution as well, but may be less accessible or well defined in comparison to those that are explicitly labeled.
See the CONTRIBUTING file for details.