2018 12 03 Founding the new UI
Over the last year, Raja has been polishing our UI including new screen layout and infrastructural improvements. We've moved the data feed to v2 in preparation of a future replacement. During our last workshop (2018-10-29 Zipkin UI at LINE Tokyo), Huy and Igarashi unveiled internal efforts towards a new UI and dedicated time towards maintaining that. Meanwhile, the LINE team have worked towards feature parity, as lack thereof has been a common cause for abandonment.
This goal of this workshop is to converge efforts into releasable open source work, owned by the community. This could be a feature branch, an optional flag deployed to the server, or possibly an outright replacement.
3 Dec 2018 during working hours in ICT (UTC +7)
5-7 Dec 2018 during working hours in JST (UTC +9)
3 Dec Ascend Corp Capital Center, Bangkok
5-7 Dec LINE HQ JR Shinjuku Miraina Tower, 23rd Floor, Tokyo
Folks attending will need to coordinate offline
We will add notes at the bottom of this document including links to things discussed and any takeaways.
The scope of this workshop assumes attendees are intimately familiar with Zipkin, as we have to discuss details of UI design.
Being physically present is welcome, but on location constrained. Remote folks can join via Gitter and attend a TBD video call.
-
Raja Sundaram Ganesan (3 Dec)
-
Adrian Cole, Pivotal
-
Huy, Line (5-7 Dec)
-
Igarashi, Line (5-7 Dec)
-
Lance Linder (5-7 Dec)
-
Max people onsite are 8!
Please review the following before the meeting
How to optionally mount the UI on nginx
Major issues:
UI should support generic and site-specific tags
Visualize large swaths of traces
We intentionally don't fill the whole day as those on site have to catch up on day job prior and after. If any segment is in bold, it will be firmly coordinated for remote folks. Other segments may be lax or completely open ended.
| 11:00am | introductions |
| 11:30am | Spike the Site Tags api |
| 5:30pm | round up |
| 6:00pm | Dinner etc |
| 10:00am | introductions |
| 1:00pm | Adrian discusses issues with rendering the tree hierarchy |
| 5:30pm | Synchronize |
| 10:00am | Start |
| 1:30pm | Review Project Lens with Nara from Netflix |
| 5:00pm | Share what we did at SoundCloud to get better service names which hugely improved usability of dependency graph and trace representation and discuss options for Line. |
Steve Conover and Kristof Adriaenssens will join remotely from Berlin, Germany. | | 5:30pm | Synchronize | | 7:00pm | Meetup at Infostellar |
| 10:00am | Start |
| 5:30pm | round up |
| 6:00pm | TBD team dinner Shinjuku |
| 9:00pm | Beers at The Watering hole |
Notes will run below here as the day progresses. Please don't write anything that shouldn't be publicly visible!
Lance
smart things (home automation can control things like power, window blinds, can control temperature, locks things). works on service to service security and also with instrumentation and zipkin. did a lot of initial work in cassandra and aws, contributes to a lot of things like ratpack. site is a cassandra based (15-16 nodes) a few TB/week with 8 day window.
Igarashi and Huy
observability team here at LINE trying to make use of Zipkin wider. Want to make it a bit more multi-tenant over time, starting with being able to customize tags. They are developing a new UI to help with this. maybe see about how to join traces higher in the architecture (need proxy to add the headers)
Raja and Adrian worked on the site tags api. It is in progress here
Added a report for the last month, which resulted in us being a bit late.
Lance mentioned that when you search for duration, the index results still show the duration breakdown of the entire trace. It is hard to know which span was the one that had the high duration. When you navigate to the trace detail screen, the context is also lost. We should figure out how to retain this information across calls. Even if this is just different colors and having a consistent color from the search page.2284
One consideration for duration search is the "spans view" tab in haystack as it can be easier to look at individual spans when hunting for one with a particular latency.
During lunch we were chatting about how to get users access to the lens code with least efforts. One driving idea was that additional configuration or deployments will limit the amount of user feedback we will get. For example, a site asked to deploy another container may choose to not deploy it at all. The previous zipkin-ui project had a separate repository and this was built into a docker container externally. There were very few users to even give feedback on this to the point that we had to attic the project. Also, right now it is easy to "java jar" a server together and test the UI. By test, I mean ask a user to verify the feature. Developers will still probably use the npm proxy to verify change they made, or run karma to execute units etc.
On the other hand, there is value in a separate build like we had before in the old zipkin-ui. Some developers seeing maven infrastructure simply won't look further to notice that it just runs npm. However, even if they did, likely they would want to run a node.js server as a unit of deployment, not a java server. This "pure node" installation could be advantageous vs deploying java servers with features disabled as it is more natural to the ecosystem. Once the lens UI is successful, we can consider an architectural option like this. By deploying to the normal server as we do today, we optimise for more end user feedback over developer ecosystem. This is something we can try later to improve.
Chat about traversals and things https://pivotal.zoom.us/j/660537177
We discussed some general topics around tree logic in the UI. Daniele found that we aren't doing depth-first traversal and so a secondary sort is needed. We also discussed that the current UI is difficult to see if there are hierarchical problems vs tools such as haystack because we don't draw causals lines (yet). When we do, we should be careful to expect data problems. This ties into a previous discussion about co-deploying zipkin-lens with the current ui codebase so that users can easily switch back and forth.
Case in point: We have timestamp order matched along with hierachical order (except latest release which has a bug). We talked about drawing causal lines like haystack, skywalking, x-ray etc as discussed in 2195. Note: the haystack ui is a bit backwards right now, but the hierarchy is still ok. Pros and cons tend to fall on balance of adding information vs cluttering the screen. Particularly in large traces adding lines can be problematic, and possibly not even adding value vs just having a collapse button such as we have today.
Huy mentioned that in a simple hierarchy you may not need to see the lines because the collapse feature hints the same. Lance mentioned that having the lines can be valuable, but it could be noisy and may be better to have the chance to turn off. Daniele showed a trace where the hierarchy is clear and there's also not much room to add lines anyway due to the trace several hundred spans. An optimization on rendering (large traces), we can turn off drawing everything like layers, except when zooming in. Tommy mentioned that the lines are more important on async operations because cause isn't strictly related to time in these cases.. it could be something to be turned on in presence of certain data.


Raja showed the stackdriver UI, which has causal lines on after you click on a span. you can click to expand or collapse a subtree.
Tommy mentioned that in the old ui project, you could see color difference on client+server spans. This gives an easy way to see latency without having to click the span detail page and should be considered for the new UI as well. https://github.com/openzipkin-attic/zipkin-ui
We talked about data problems in general, such as if instrumentation are causing some issues that the UI can work around, but should be fixed. One topic is that we want the users to be unaware of problems so they neither distrust the UI nor become scared of it. This could hint at an overlay or a job to find sources of bad data.
Daniele mentioned that the previous react ui zipkin-view had some nice features, for example it could tell you if you had missing spans. It had a hierarchical lines between the parent and child as well. Finally, they added a favorite trace button to it. However, the zipkin-view app is stuck on v1 api so it can't be run with the latest server anymore. To this point, it would be good to get the conversion libraries published on npm soon so that other UIs can use them.
about things on the same line https://github.com/openzipkin/zipkin/issues/1701
https://pivotal.zoom.us/j/548231918
Code review of Zipkin Lens with Igarashi and Huy. Folks joining remotely were Nara, Raja, Tommy with Adrian and Lance onsite.
Huy introduces Igarashi and himself and their role at LINE. Describes overview of Zipkin Lens tech stack and UI layout. The new UI is build with React, ChartJS, Vizceral and a handful of custom built UI components and compiles with NodeJS, NPM and Webpack.
Zipkin Lens consumes the V2 Zipkin API without any additional changes. The UI introduces a scatter graph showing span latency over time with clickable data points so users can drill into specific traces. Another feature is the removal of span details popup and instead renders span details inline within the trace view. There is a new zoom feature that allows for narrowing into a specific section within a large span tree. Each service has a random color associate with it to allow for quicker identification of services involved in the trace.
New dependency graph uses Netflix Vizceral and adds additional details panel with success/error counts along with a service search input.
Adrian suggests that we should host both UIs in the main Zipkin server jar and allow users to select either UI to test both views on real data. Also suggests there might be some confusion about new features and it would help adoption by allowing users to revert to old UI as docs and familiarity matures. Another suggestion Adrian brought up is to create a standalone Docker image that checks out and builds Zipkin Lens for folks that prefer deploying the UI with that approach.
Some other feedback mentioned is to keep UI search state in the URL query parameters to make sharing specific searches easier. It was also discussed that the zoom level should also be in the URL to make fine grained sharing possible.
Nara asked about coloring spans based on error state. In the current UI adding an "error" tag to a span will color the entire span bar red in the UI. Zipkin Lens carries this functionality forward and also colors "error" spans red.
Discussed that the dependency graph can be too busy and that having some way to filter out sections of the graph based on root services would be helpful. Adrian suggests that partitioning the graph by root services would may be possible. Nara suggests that when troubleshooting problems it is often easiest to start at a specific service and drill down to other services, which is a similar feature that Newrelic has. Another enhancement for the future would be to add hooks or plugins to external metrics systems where the UI could display additional data based on service names etc. Adrian suggests we should catalog these integration requests to determine what might be useful for users.
Huy demos site tags feature which is not yet in the main branch. Site tags can be used as hints in the trace search form. For example at LINE they tag spans with instance ID which can later be used during search. In Haystack UI these are presented in the search input with autocomplete on low cardinality tags. Adrian mentions that Raja is working on a new endpoint in Zipkin just for search tags.
Adrian discussed features of Haystack and how it works with Zipkin data. Also mentions some issues with stability and growing pains, which may partially be due to things living in separate source code repos making feature drift and bugs more likely.
Nara brought up that sampling constrains limit certain use cases and that it has an impact on how the data can be used.
Steve mentioned that for parent-child links, the least bad representation is the core diagram, where there's a circular relationship. Rooted dependency links might help solve problems around knowing who established the sample rate.
2 major use cases in tracing: discover the architecture (higher level abstraction), and then search.. these represent 80% of the value.
Steve likes the usability improvements to see multiple traces, Lance like the idea to co-plot traces using the same screen as the trace list.
From deployment options, it is easy enough using the spring boot approach. That way we can do it in local development easier vs docker.
![]() haystack screenshot.png (image/png)
haystack screenshot.png (image/png)
![]() zipkin screenshot.png (image/png)
zipkin screenshot.png (image/png)
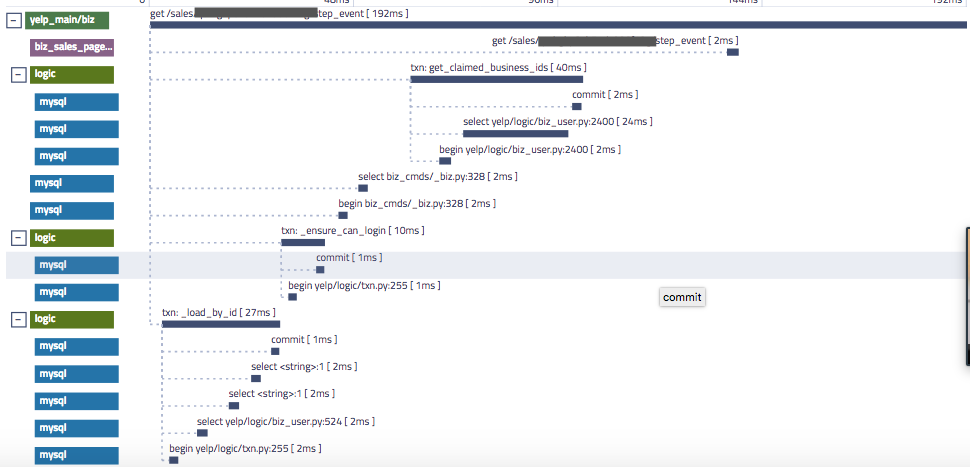
![]() スクリーンショット 2018-12-05 14.48.56.png (image/png)
スクリーンショット 2018-12-05 14.48.56.png (image/png)
{kind=link}
{kind=link}
{kind=link}