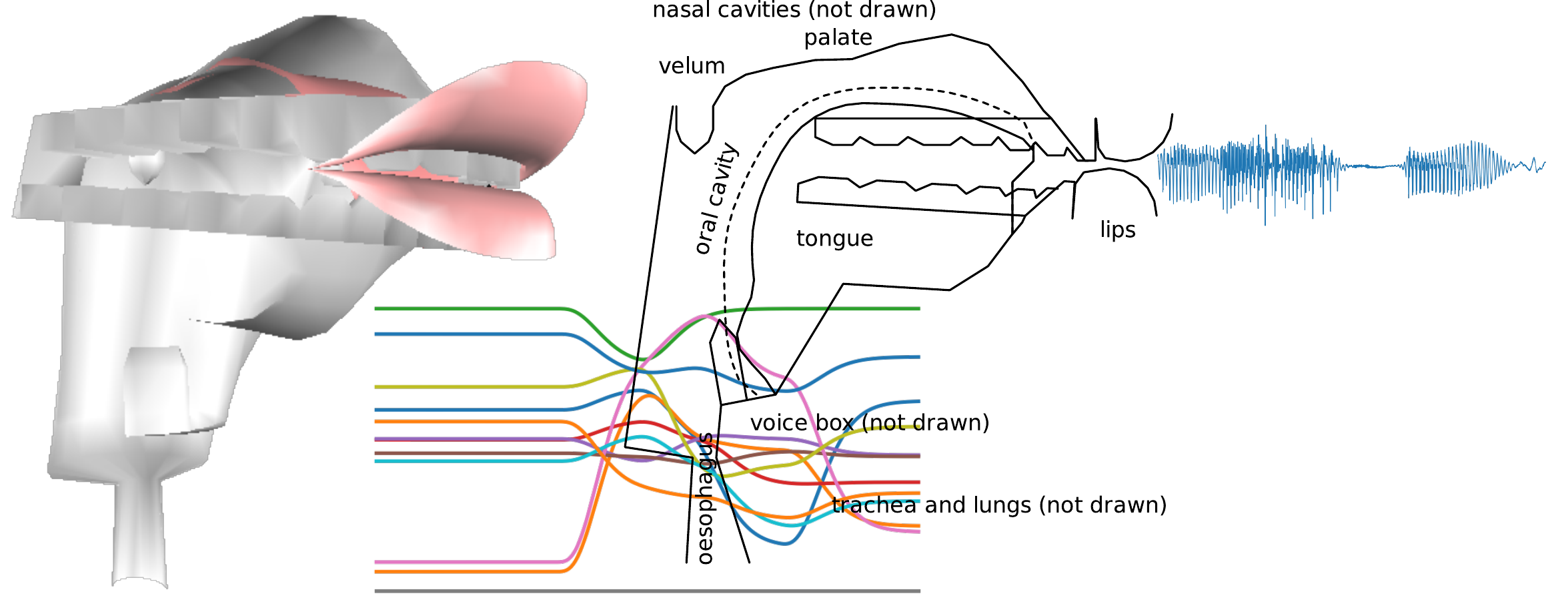
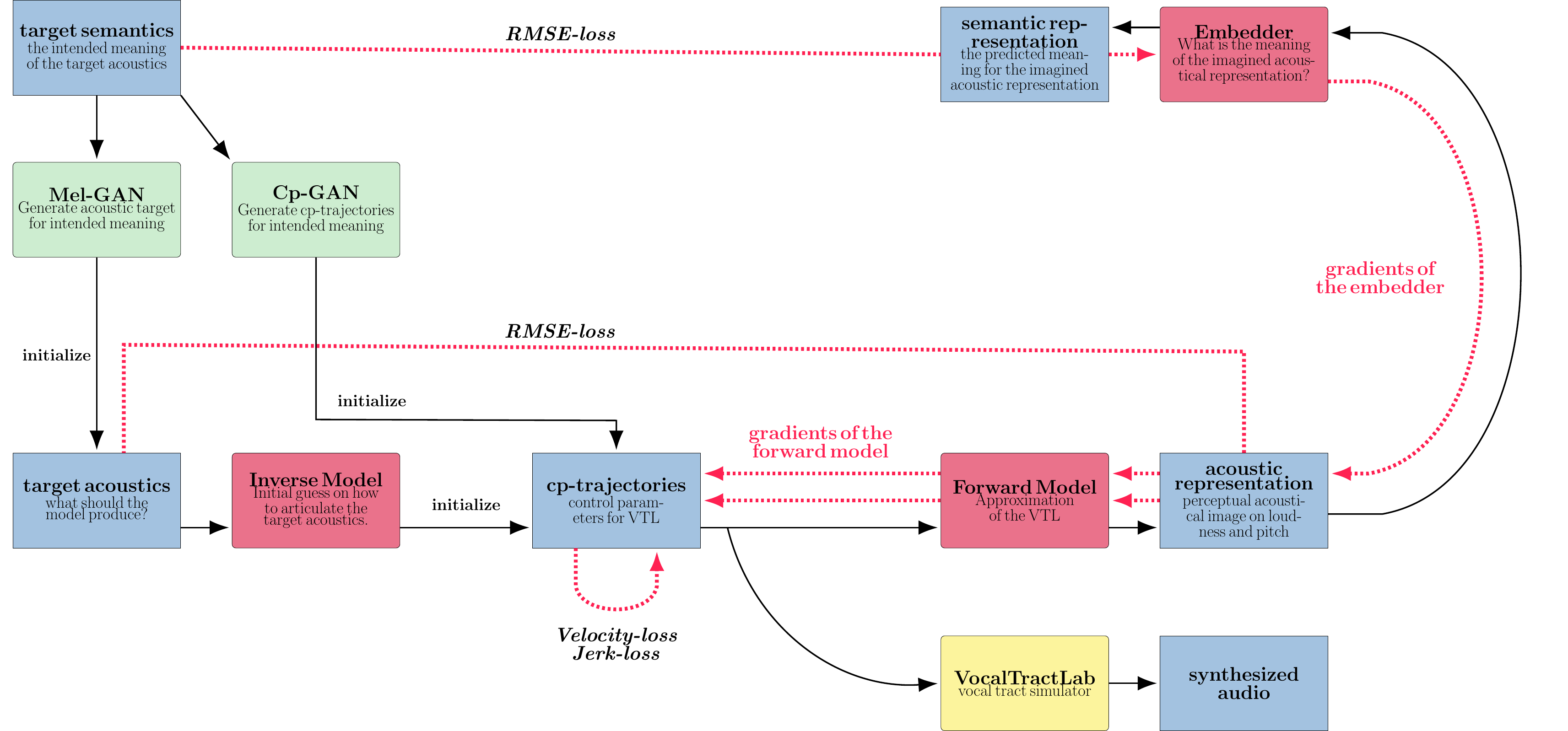
Predictive Articulatory speech synthesis Utilizing Lexical Embeddings (PAULE) a python frame work to plan control parameter trajectories for the VocalTractLab simulator for a target acoustics or semantic embedding.
pip install paule
A minimal example can be found at https://raw.githubusercontent.com/quantling/paule/main/docs/examples/minimal_example.py
To cite the PAULE model use:
@book{PAULEthesis,
title = "{P}redictive {A}rticulatory speech synthesis {U}tilizing {L}exical {E}mbeddings ({PAULE})",
author = "Sering, Konstantin",
year = 2023,
publisher = "Universität Tübingen",
address = "Tübingen",
doi = {10.15496/publikation-90142}
}
To cite the PAULE source code use the DOI 10.5281/zenodo.7252431 (https://zenodo.org/doi/10.5281/zenodo.7252431), if you want to cite the software in general or the specific DOI on Zenodo.
This research was supported by an ERC advanced Grant (no. 742545), by the DfG grant 527671319 ("Komplexe Wörter im Kontext“), and the University of Tübingen.