refactor: refactor source executor (part 1) #15103
Conversation
|
Current dependencies on/for this PR:
This stack of pull requests is managed by Graphite. |

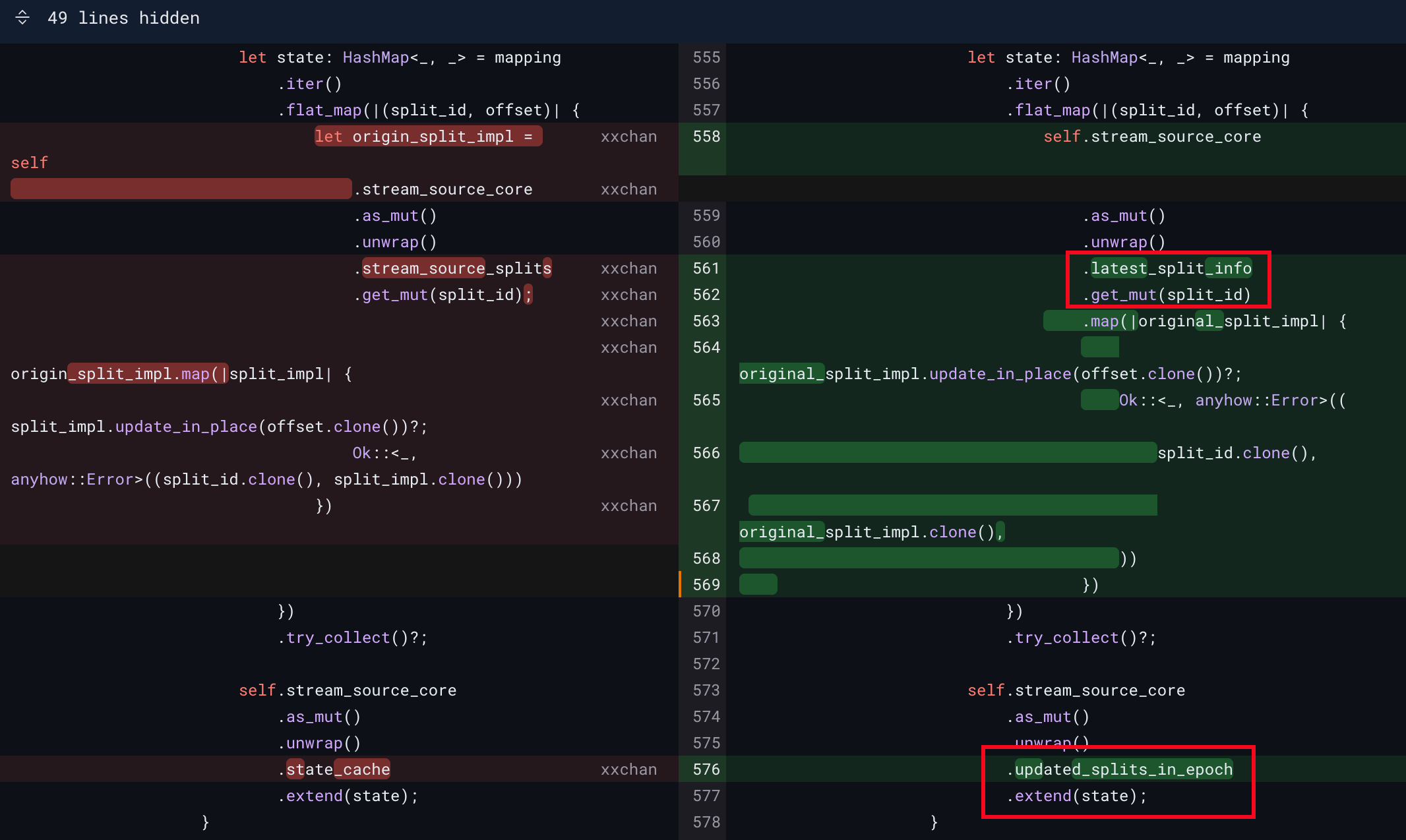
| self.stream_source_core.latest_split_info.get_mut(id).map( | ||
| |origin_split| { | ||
| origin_split.update_in_place(offset.clone())?; | ||
| Ok::<_, anyhow::Error>((id.clone(), origin_split.clone())) | ||
| }, | ||
| ) | ||
| }) | ||
| .try_collect()?; | ||
|
|
||
| self.stream_source_core.state_cache.extend(state); | ||
| self.stream_source_core | ||
| .updated_splits_in_epoch | ||
| .extend(state); |
There was a problem hiding this comment.
We can see they are updated in the same way on data chunk. Plan to unify them later.
| // fetch the newest offset, either it's in cache (before barrier) | ||
| // or in state table (just after barrier) | ||
| let target_state = if core.state_cache.is_empty() { | ||
| for ele in &mut *split_info { | ||
| if let Some(recover_state) = core | ||
| .split_state_store | ||
| .try_recover_from_state_store(ele) | ||
| .await? | ||
| { | ||
| *ele = recover_state; | ||
| } | ||
| } | ||
| split_info.to_owned() | ||
| } else { | ||
| core.state_cache | ||
| .values() | ||
| .map(|split_impl| split_impl.to_owned()) | ||
| .collect_vec() | ||
| }; | ||
|
|
There was a problem hiding this comment.
Actually this is a bug: When state_cache is some, we shouldn't use it to rebuild stream reader, since it only contains splits updated in this epoch.
There was a problem hiding this comment.
However, this is hard to trigger. In my local testing I found that rebuild_stream_reader_from_error isn't triggered even when external Kafka/PG is killed...
There was a problem hiding this comment.
Actually this is a bug: When state_cache is some, we shouldn't use it to rebuild stream reader, since it only contains splits updated in this epoch.
Source attempts to recover from the latest successful offset so we always recover from cache.
The case you mentioned above occurs when some partitions have no new data in one epoch, which means partitioning imbalance and this can hardly happen in MQs.
There was a problem hiding this comment.
In my local testing I found that rebuild_stream_reader_from_error isn't triggered even when external Kafka/PG is killed...
Kafka SDK handle Kafka broker timeout internally and will keep trying to reconnect. For kinesis, the logic will be triggered when network issue happens. 😇
There was a problem hiding this comment.
when some partitions have no new data in one epoch, which means partitioning imbalance and this can hardly happen in MQs.
I think It's not that impossible. Imagine the source is idle for a while, and then only 1 message is produced. Can also happen if user's key is imbalanced according to their bussiness logic.
| if let Some(target_state) = &target_state { | ||
| latest_split_info = target_state.clone(); | ||
| } | ||
|
|
There was a problem hiding this comment.
I think the local variable latest_split_info can be replaced by the field.
|
|
||
| let target_state = core.latest_split_info.values().cloned().collect(); |
There was a problem hiding this comment.
I have some correctness concerns here. Seems you are resetting the process to the offset where the last successful barrier came, taking the time as T0.
But later an error occurs at time T1 and requires rebuilding source internally. The logic here may lead to read data from T0 to T1 twice.
There was a problem hiding this comment.
I think the expected logic here is taking a union of both state_cache and split_info to make sure resetting every assigned split to its latest offset.
There was a problem hiding this comment.
Seems you are resetting the process to the offset where the last successful barrier came
No. latest_split_info is also updated on every message chunk, so its offset is always up to date.
There was a problem hiding this comment.
This is indeed very confusing and also why I wanted to use just one.
| // state cache may be stale | ||
| for existing_split_id in core.stream_source_splits.keys() { | ||
| // Checks dropped splits | ||
| for existing_split_id in core.latest_split_info.keys() { |
There was a problem hiding this comment.
also delete removed items in latest_split_info here because it is seen as the ground truth of split assignment when doing recovery internally.
There was a problem hiding this comment.
Actually it is updated later in persist_state_and_clear_cache using target_state.. This is how it works previously. This PR doesn't want to change it. #15104 just changes this.
This reverts commit 3ce0996.
This reverts commit 3ce0996.
I hereby agree to the terms of the RisingWave Labs, Inc. Contributor License Agreement.
What's changed and what's your intention?
Rename
stream_source_splitsandstate_cacheaccording to how they are updated.They are very similar and can be wrongly used. Actually only one of them may be enough. This PR only does the renaming first to make it easy to review.
Checklist
./risedev check(or alias,./risedev c)Documentation
Release note
If this PR includes changes that directly affect users or other significant modifications relevant to the community, kindly draft a release note to provide a concise summary of these changes. Please prioritize highlighting the impact these changes will have on users.